2026年、機械学習とテストは、疾病診断からグローバル金融の基盤に至るまで、重要システムの核心を担っている。これらのモデルが失敗した場合、深刻な結果を招く——収益の損失、評判の毀損、さらには規制当局による罰則さえも。
組織がイノベーション推進のために機械学習とテストへの依存度を高める中、信頼性とコンプライアンスの確保はかつてないほど重要となっている。にもかかわらず、多くのチームは依然として、これらのシステムがもたらす特有の課題に対処するのに苦労している。
本ガイドでは、機械学習とテストのベストプラクティスをわかりやすく解説し、MLワークフローの検証・自動化・将来を見据えた設計に向けた明確な手順を提供します。モデル構築からデプロイ管理まで、信頼性の高い結果を得るための実践的な戦略が得られます。
2026年における機械学習テストの進化する状況
2026年、機械学習とテストの関係は劇的に変化しました。組織が重要な業務でMLシステムへの依存度を高めるにつれ、堅牢な検証の重要性はかつてないほど高まっています。企業は技術的課題と規制上の課題の両方に直面しており、信頼性と信頼性を確保するためには、高度な機械学習とテストの実践が不可欠となっています。

従来型テストから機械学習特化型テストへの移行
従来のソフトウェアテストは決定論的ロジックに依存し、同じ入力が常に同じ出力を生み出す。これに対し、機械学習とテストでは、絶えず変化するデータとモデルによって駆動される確率的な結果を考慮しなければならない。この移行は、データが進化するにつれて機械学習システムが予測不能な挙動を示す可能性があるため、重大な複雑性を伴う。
典型的な例として、医療分野の機械学習モデルが挙げられる。初期段階では良好な性能を発揮していたが、患者の人口統計が変化した際に精度が急落する現象(データドリフト)が発生した。従来のアプリケーションとは異なり、機械学習とテストでは安全性と有効性を確保するため、こうした変化を継続的に監視する必要がある。
この複雑性は、産業全体での機械学習の大量導入によって増幅される。ガートナー(2025年)によれば、現在90%の企業がミッションクリティカルなワークフローに機械学習を導入している。EU AI法などの規制環境は説明可能性と厳格な検証を要求しており、コンプライアンスが機械学習およびテストチームの中核的課題となっている。
MLOpsの台頭により、DevOpsの原則が機械学習ライフサイクルとさらに統合されました。テストは開発パイプラインに組み込まれた継続的かつ自動化されたプロセスへと進化しています。これらの進化する実践の包括的な概要については、『MLOps究極ガイド:プロセス、成熟度、ベストプラクティス』が、組織が機械学習とテストのワークフローをいかに成熟させているかについて貴重な洞察を提供します。
しかし、固有の課題は依然として存在します:
- 多様なデータソースにおける高品質データの確保
- モデルドリフトの検出と対応
- 結果の再現性の達成
これらの課題は、機械学習とテストが従来のソフトウェアQAでは提供できない専門的な戦略を必要とする理由を浮き彫りにしている。
2026年の機械学習テストにおける中核的目標
機械学習とテストの複雑化が進む中、明確な目標設定が不可欠です。エラーの早期発見は、下流工程のコスト削減と手戻り防止に極めて重要です。堅牢なテストは、モデルの汎化性能の確保、公平性の維持、倫理基準への準拠を保証します。
信頼性も重要な目標である。特に本番環境ではコード、データ、モデルが頻繁に変更されるためだ。機械学習とテストは迅速な反復と革新を支えつつ、安全性やコンプライアンスを損なわないことが求められる。
実例を考えてみましょう:あるオンライン小売業者のレコメンダーシステムが、定期的な更新後に回帰バグを発生させました。売り上げは落ち込み、顧客の信頼は損なわれました。回帰テストや行動テストなどの包括的な機械学習とテストの実践を通じて、こうした問題はビジネスに影響を与える前に検出・解決できます。
2026年の主要目標は以下の通りです:
- エラーの早期検出と予防
- 多様なデータ分布における汎化性の確保
- 公平性と倫理的コンプライアンス
- 頻繁な更新時の信頼性
- リスクを最小限に抑えながら迅速なイノベーションを実現
高度な機械学習とテスト手法を優先する組織は、長期的な成功を収める基盤を築く。環境が進化し続ける中、堅牢な検証、継続的モニタリング、適応型テストフレームワークへの投資は、信頼性が高くスケーラブルな機械学習システムにとって不可欠となる。
機械学習システム向けテストの種類
効果的な機械学習とテストには、テストの全範囲を理解することが不可欠である。MLシステムの複雑性が増すにつれ、チームは従来のソフトウェアテストとML固有のアプローチを組み合わせる必要がある。これにより、コードからデータ、モデルに至るまで、あらゆる構成要素が堅牢かつ信頼性のある状態が保証される。
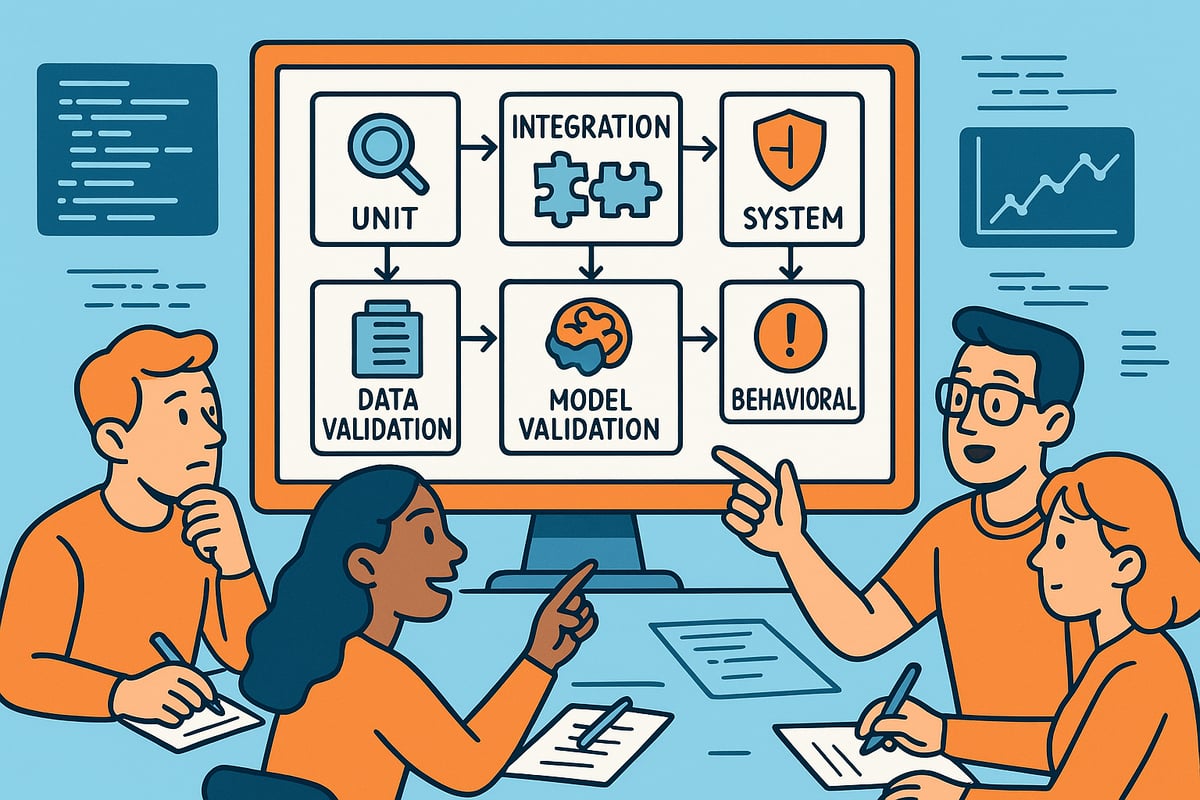
単体テスト、統合テスト、システムテスト、受け入れテスト
機械学習とテストの基盤は、古典的なソフトウェアテストの種類から始まります。ユニットテストは、機能のスケーリング手法やデータクリーニング機能など、個々のコード機能やコンポーネントを検証します。これらのテストはバグを早期に発見し、独立したロジックに対する信頼性を構築するのに役立ちます。
統合テストは、データ前処理、特徴量エンジニアリング、モデル推論など、機械学習パイプラインの複数の部分が円滑に連携することを保証します。例えば、統合テストによってデータスキーマの不一致が検出され、実行時にパイプラインが停止する事態を防げる場合があります。
システムテストは、生データの取り込みからモデルのサービングに至るエンドツーエンドのワークフローを評価します。これにより、本番環境に近い状態で機械学習とテストのプロセス全体が期待される結果を確実に提供することを確認します。
受け入れテスト(またはユーザーテスト)は、システムがビジネス要件や規制基準を満たしていることを検証します。例えば、不正検知モデルがコンプライアンス基準を満たしているか、AIチャットボットがユーザーの問い合わせに正確に応答しているかなどを確認します。
回帰テストは、新たな変更によって過去に修正されたバグが再発しないことを保証する点で、機械学習とテストにおいて極めて重要な役割を果たします。例えば、レコメンデーションアルゴリズムを更新した後、回帰テストによって重複した提案などの過去の問題が再発しないことを確認します。
各テストタイプが機械学習とテストにどのように適合するかをまとめた表は以下の通りです:
| テストの種類 | 重点領域 | 典型的な例 |
|---|---|---|
| ユニット | コード関数 | テスト機能の正規化 |
| 統合 | パイプラインコンポーネント | データ前処理 + モデル推論 |
| システム | エンドツーエンドワークフロー | 生データから予測提供まで |
| 受入 | ビジネス/規制 | GDPR準拠を満たす |
| 回帰 | バグ防止 | 既知の問題の再発を防止 |
スケーリング関数のシンプルな単体テストは以下のようなものになる:
def test_scaling_negative():
assert scale(-5) == expected_output
機械学習とテストは、この基盤によって早期のエラー検出と迅速な反復を支援する恩恵を受けます。これらの原則についてさらに詳しく知りたい場合は、こちらのソフトウェアおよびシステムテストの概要をご覧ください。
機械学習に特化したテスト手法
従来のソフトウェアテストを超え、機械学習とテストにはデータ駆動型の課題に対処するための専門的なアプローチが必要です。データ検証テストは極めて重要であり、入力データが期待される型、範囲、分布に合致していることを確認します。例えば、欠損値の急激な増加がモデルの信頼性を脅かす場合、テストがこれを指摘することがあります。
モデル検証テストは、モデルの精度、正確性、再現率、公平性を評価します。これらのテストにより、トレーニング済みモデルが適切に一般化され、バイアスを導入していないことをチームが確認できます。例えば、モデル検証テストにより、特定のユーザーグループに対して新しいモデルバージョンが劣った性能を示すかどうかを明らかにできます。
行動テストは実世界シナリオをシミュレートし、多様な条件下でモデルが期待通りに動作することを保証します。例えば、これらのテストではモデル安定性を検証するため、稀な例や敵対的例を導入することがあります。
統計的テストは、過学習、過少学習、データリークを検出するために不可欠です。特に新しいデータが導入される中で、時間の経過に伴うモデルの完全性を維持するのに役立ちます。
機械学習とテストで使用される専門的なテストの種類を以下に示します:
- データ検証:スキーマチェック、欠損値検出、分布分析
- モデル検証:性能指標、公平性、頑健性チェック
- 行動ベース: エッジケースシミュレーション、敵対的入力シナリオ
- 統計的テスト:ドリフト検出、情報漏洩の特定
機械学習とテストは、これらの専門的なテストを自動化しパイプラインに統合することで最も効果を発揮します。このアプローチにより一貫した品質が確保され、サイレント失敗が防止され、進化する業界標準への準拠が支援されます。
MLテストのベストプラクティス実装ステップバイステップガイド
2026年において、信頼性の高いAIシステム構築には機械学習とテストが不可分となっています。明確で構造化されたアプローチに従うことで、モデルが信頼できる結果を提供し、変化に適応し、規制に準拠することを保証できます。プロセスを段階的に分解してみましょう。

ステップ1:テストフレームワークとツールの確立
効果的な機械学習とテストには強固な基盤が不可欠です。まず、スタックに適したテストフレームワークを選択します。pytest、unittest、Great Expectationsなどの機械学習特化ツールが一般的な選択肢です。コード、データ、モデルを網羅するテスト専用のディレクトリでプロジェクトを整理します。
テストスイートをCI/CDパイプラインと統合し、検出と実行を自動化します。例えばpytest設定では、フィクスチャとパラメータ化テストを活用してセットアップを効率化できます:
import pytest
@pytest.fixture
def sample_data():
return [1, 2, 3]
def test_sum(sample_data):
assert sum(sample_data) == 6
基盤となる原則の包括的な概要については、堅牢な機械学習とテストのための必須戦略を網羅した「MLOps Principles」の参照をご検討ください。
ステップ2: テストコードのアーティファクト
次に焦点を当てるのはコード品質です。正確なユニットテストを容易にするため、単一責任の関数やクラスを記述してください。すべての入力・出力型の検証、例外処理、エッジケースのカバーを確実に行ってください。
再利用可能なテストモジュールのための中央リポジトリを維持する。このアプローチにより開発が加速され、プロジェクト間の一貫性が向上する。例えば、機能スケーリング関数のユニットテストでは予期しない負の値を捕捉でき、下流の問題を防止できる。
- 関数の出力が想定範囲内であることを検証する。
- 無効な入力による例外をテストする。
- チーム全体で共通のテストユーティリティを再利用する。
あらゆる機械学習およびテストの取り組みは、厳密で再利用可能なコードテストによって恩恵を受ける。
ステップ3: データの品質と完全性を検証する
データは機械学習とテストの中核です。スキーマチェックを実施し、データ型と構造が期待通りであることを保証します。値範囲チェックとNULL検出を活用し、モデルに到達する前に異常を検知します。
統計的テストによりデータドリフトや急激な異常を監視できます。データ取り込みパイプラインでこれらのチェックを自動化し、問題を早期に捕捉しましょう。例えば、欠損値の急増を検知してアラートを発し、モデルの劣化を防ぐことが可能です。
- 明確なデータ要件を定義する。
- 一般的なデータ問題に対する自動チェックを設定する。
- 検証をデータ処理ワークフローに統合する。
継続的なデータ検証により、機械学習とテストプロセスが堅牢性を維持します。
ステップ4: モデル成果物のテスト
モデルのテストは、性能、公平性、信頼性を維持するために不可欠です。精度、正確性、再現率、公平性指標などのメトリクスを用いてモデルの出力を評価します。回帰テストは、更新によって古いバグやバイアスが再導入されないことを保証するために重要です。
行動テストでは現実世界や敵対的シナリオをシミュレートし、モデルを限界まで追い込みます。例えば融資審査モデルで回帰テストを実行すれば、更新によって意図せずバイアスが再導入されないことを確認できます。
- モデルのパフォーマンスを時間経過とともに追跡する。
- エッジケースや敵対的入力をシミュレートします。
- モデル評価結果の履歴を保持する。
モデル成果物の徹底的なテストは、機械学習とテストの成功の中核をなす要素である。
ステップ5:MLワークフローにおけるテストの自動化と統合
自動化は効率的な機械学習とテストの基盤である。コードコミット、データ変更、モデル更新のたびに自動テスト実行を設定する。pre-commitフックやGitHub Actionsなどのツールを活用し、継続的な検証を確保する。
テストカバレッジを監視し、不足箇所を事前に解消しましょう。自動化されたパイプラインはデプロイ前の統合バグを捕捉できるため、本番環境に高額な問題が到達するリスクを低減します。
- 機械学習ライフサイクルの全段階でテストを自動化します。
- ダッシュボードでカバレッジと結果を監視する。
- テスト失敗や異常発生時にアラートをトリガーする。
自動化により、機械学習とテストのワークフローが俊敏性と信頼性を維持します。
ステップ6: テストスイートの文書化と維持
文書化は機械学習とテスト手法の持続可能性を支えます。各テストケースの目的と期待される結果を含め、明確に文書化してください。データやモデルロジックが進化するにつれ、テストを定期的に更新します。
テスト結果、失敗事例、変更点を経時的に追跡する。適切に管理されたドキュメントは、新規メンバーの受け入れと継続的改善を加速させる。例えば、新メンバーが加わった際、明確なテスト文書があれば、テストの根拠を迅速に理解できる。
- テストケースのドキュメントを常に最新の状態に保つ。
- 主要な変更ごとにテストを見直し、改訂してください。
- コードとテスト成果物の両方にバージョン管理を活用する。
一貫したドキュメント作成は、機械学習とテストの実践をスケーラブルかつ将来を見据えたものにする最終段階である。
信頼性と拡張性を備えた機械学習テストのベストプラクティス
信頼性と拡張性を備えたシステムの構築は、機械学習とテストの取り組みを成功させる基盤です。モデルやデータパイプラインが複雑化する中、実証済みのベストプラクティスに従うことで、MLソリューションの堅牢性、保守性、そして企業レベルの要求への対応力を維持できます。

効果的な機械学習テストの原則
効果的な機械学習とテストには、確固たる原則の遵守が不可欠です。以下の表は、全てのMLチームが採用すべき中核的実践をまとめたものです:
| 原則 | 説明 |
|---|---|
| アトミックデザイン | 関数やクラスは単一の責任を担うことで、テストを簡素化します。 |
| テストの構成 | 新しいコンポーネントと並行して新しいテストを記述し、シームレスな統合を実現する。 |
| 再利用性 | テストロジックを一元化し、一貫性と効率性を確保する。 |
| 回帰管理 | 発見されたバグごとに的を絞ったテストを追加し、再発を防止します。 |
| カバレッジ指標 | カバレッジを追跡するが、コードベースにテストを過度に適合させることは避ける。 |
| 自動化 | 信頼性の高い実施のため、テストをCI/CDに統合する。 |
機械学習とテストへの実践的なアプローチは、原子的でテストしやすいコードを書くことから始まる。例えば、Pythonの正規化関数に対するシンプルな単体テストは次のようになる:
def test_normalize_min_max():
data = [0, 50, 100]
result = normalize_min_max(data)
assert result == [0.0, 0.5, 1.0]
自動化は機械学習とテストのゲームチェンジャーです。CI/CDワークフローにテスト実行を組み込むことで、問題を早期に発見し一貫した品質を維持できます。自動化のトレンドと高度なMLOps戦略についてさらに深く知りたい場合は、「2026年に注目すべき5つの最先端MLOps技術」を参照してください。
堅牢な機械学習とテストの実践は、新規プロジェクトやチームメンバーのオンボーディング時間を劇的に短縮できることを覚えておいてください。
よくある落とし穴とその回避方法
最善の努力にもかかわらず、チームは機械学習とテストの取り組みを損なう落とし穴にしばしば直面します。予防には認識と積極的な行動が鍵となります:
- データ検証を省略すると、静かに進行する高コストなモデル障害を引き起こす可能性があります。
- 行動テストを軽視すると、エッジケースが未対応のまま放置される可能性があります。
- 手動テストへの依存はリリースを遅らせ、見落としリスクを高める。
- 陳腐化したテストスイートは進化するデータやモデルロジックを反映できず、誤検知を引き起こす。
- 回帰テストの省略は、更新後に古いバグが再発する原因となります。
これらの落とし穴を避けるには、データパイプラインからモデルデプロイメントまでの全段階で検証を自動化すること。モデルやデータの変更に伴いテストスイートを定期的に更新すること。行動テストと回帰テストは後回しにするのではなく、優先すべき事項である。
機械学習とテストに対する規律あるアプローチ、特に継続的改善に焦点を当てることで、要件が変化してもMLシステムが一貫した信頼性の高い結果を提供し続けることが保証されます。
機械学習テストにおける高度な技術と新たな動向
2026年、組織がAI導入の限界を押し広げる中、高度な機械学習とテスト戦略が不可欠です。モデルがより重要なビジネス判断に影響を与えるにつれ、高度なテスト技術が公平性、透明性、回復力を保証します。機械学習とテストの未来を形作る3つの新たな柱を分解してみましょう。
公平性、バイアス、説明可能性のためのテスト
公平性と透明性の確保は、機械学習およびテストの専門家にとって最優先事項となっている。現代のフレームワークでは、人口統計的公平性や機会均等といった公平性指標が組み込まれ、敏感なグループ全体でのパフォーマンスを追跡している。自動化されたバイアス検出ツールはデータとモデル出力をスキャンし、潜在的な偏見を検知することで、チームが規制や倫理的要件に対応するのを支援する。
説明可能性も同様に不可欠である。SHAPやLIMEといったツールは、モデルが意思決定を行う過程を明確かつ解釈可能な形で分解し、コンプライアンスとステークホルダーの信頼の両方を支える。例えば、公平性監査により採用モデルが特定のデモグラフィックを優遇していることが判明した場合、即座に是正措置が講じられることになる。
これらの概念の基礎を強化したい場合は、機械学習基礎コースが現代のMLパイプラインにおける公平性と説明可能性に関する実践的知見を提供します。機械学習とテストワークフローにこれらの実践を組み込むことで、組織はバイアスから保護され、透明性を維持できます。
本番環境における監視とテスト
本番環境では機械学習とテストに特有の課題が生じます。デプロイ前のテストで多くの問題は検出されますが、実世界のデータが予期せぬ問題を引き起こす可能性があります。チームは現在、モデルの継続的な信頼性を確保するため、オフライン検証とデプロイ後のアクティブな監視を区別しています。
高度な監視システムはデータドリフト、モデルドリフト、予期せぬ性能低下を追跡する。メトリクスが安全範囲を外れた場合、自動トリガーがデプロイのロールバックや再トレーニングを起動する。例えば本番モデルが顧客行動の変化を検知すると、自動アラートがチームに調査を促し、必要に応じて再トレーニングを実施する。
この機械学習とテストに対する積極的なアプローチにより、モデルは堅牢性と正確性を維持し、ビジネス目標に沿った状態を保ちます。一貫した監視と迅速な対応は、現在では高リスクな実世界の機械学習システムにおける標準となっています。
将来の動向:AI強化型テストと自己修復システム
機械学習とテストの未来は急速に進化している。AI搭載ツールはテストケースを生成し、手動テスターが見逃す可能性のあるエッジケースを発見できる。これらのシステムは異常検知を活用し、大規模データセット内の微妙な問題を特定することで、より網羅的な検証を支援する。
自己修復型機械学習システムが登場しつつあり、本番環境でテスト失敗が発生した際に自動的に修正したりチームに警告したりできる。この変化により、テストがモデルガバナンスやコンプライアンスワークフローと統合され、大規模なトレーサビリティと監査可能性が確保されるようになっている。
エンジニアリングリーダーにとって、これらのトレンドを理解することは極めて重要です。『2025年エンジニアリングリーダーのためのMLOpsベストプラクティスTOP10』は、堅牢な機械学習とテストプロセスを実装するための実践的戦略を提供します。AI強化型テストと自己修復機能の採用は、組織が信頼性と革新性の両面で優位に立つことを可能にします。
事例研究と実世界の例
あらゆる業界において、機械学習とテストはビジネスのレジリエンスとイノベーションに不可欠であることが証明されています。実例は、包括的なテストフレームワークへの投資によって組織が成果をどのように変革しているかを明らかにします。
業界リーダーから学ぶ教訓
業界リーダーたちは、堅牢な機械学習とテスト実践がパフォーマンス、信頼性、コンプライアンスを直接向上させ得ることを実証しています。例えば、大手eコマースプラットフォームは階層化されたMLテスト戦略を導入し、システムダウンタイムを60%削減しました。同チームは回帰テストと統合テストの自動化に注力し、コード、データ、モデルの変更がリリース前に確実に検証される体制を構築しました。
ある大手金融機関は、検出されなかったデータドリフトによる高額な予測誤差に直面しました。自動回帰テストの採用と継続的データ検証チェックの統合により、収益損失を防止しただけでなく、AI駆動型サービスへの信頼性を高めました。この文脈では、データエンジニアリングと機械学習マスタークラスで教示されている包括的なデータパイプラインへの投資が、テストと統合プロセスを大幅に強化し得ます。
医療AIスタートアップは厳格な規制監査への対応を必要としていた。行動テストを用いて現実の患者シナリオをシミュレートし、多様な条件下でも診断モデルの信頼性を維持した。これらの事例は、機械学習とテストが組織の高コストな失敗回避と高水準達成に如何に貢献し得るかを示している。
定量的成果
成熟した機械学習とテスト導入の結果は測定可能です。Forrester(2025年)によれば、自動化された機械学習テストを導入した企業はデプロイサイクルが30%短縮されています。さらに、データ検証・監視ツールを活用する組織では、デプロイ後のモデル障害が70%減少しています。
| 指標 | 影響 |
|---|---|
| デプロイ速度 | 自動化により30%高速化 |
| デプロイ後のモデル障害 | 70%削減 |
| 顧客クレーム(AI搭載サービス) | 堅牢なテスト実施後、40%減少 |
例えば、行動テストと回帰テストを統合した結果、AI搭載サービスにおける顧客クレームが40%減少しました。こうした定量的な成果は、機械学習とテストが単なるベストプラクティスではなく、ビジネスの成功と信頼性を支える重要な推進力であることを裏付けています。
ご覧の通り、2026年に信頼性が高く倫理的で拡張性のあるAIシステムを構築するには、機械学習テストの習得が不可欠です。組織のワークフロー改善を目指す場合でも、自身のスキル向上を目指す場合でも、適切な基盤が全てを決定づけます。 ベストプラクティスを実際の成果に変え、急速に進化するAI分野で差別化を図る準備ができていますか?次のステップを踏み出しましょう。今すぐ認定AI基礎スペシャリストへの道を歩み始められます。無料で始められます。