W 2026 r. uczenie maszynowe i testowanie stanowią sedno systemów krytycznych, od diagnozowania chorób po zasilanie globalnych finansów. Gdy modele te zawodzą, konsekwencje są poważne — utrata przychodów, utrata reputacji, a nawet kary regulacyjne.
Ponieważ organizacje w coraz większym stopniu polegają na uczeniu maszynowym i testowaniu w celu stymulowania innowacji, zapewnienie niezawodności i zgodności z przepisami nigdy nie było tak ważne. Jednak wiele zespołów nadal boryka się z wyjątkowymi wyzwaniami, jakie stawiają te systemy.
Niniejszy przewodnik wyjaśnia najlepsze praktyki w zakresie uczenia maszynowego i testowania, oferując jasne kroki umożliwiające walidację, automatyzację i zabezpieczenie przyszłościowych procesów ML. Niezależnie od tego, czy tworzysz modele, czy nadzorujesz wdrożenia, znajdziesz tu praktyczne strategie zapewniające niezawodne wyniki.
Ewolucja testowania uczenia maszynowego w 2026 r.
W 2026 r. relacje między uczeniem maszynowym a testowaniem uległy radykalnej zmianie. Ponieważ organizacje w coraz większym stopniu polegają na systemach ML w zakresie krytycznych operacji, stawka związana z solidną walidacją nigdy nie była wyższa. Przedsiębiorstwa stoją przed wyzwaniami zarówno technicznymi, jak i regulacyjnymi, co sprawia, że zaawansowane praktyki uczenia maszynowego i testowania mają zasadnicze znaczenie dla niezawodności i zaufania.

Przejście od testowania tradycyjnego do testowania specyficznego dla ML
Tradycyjne testowanie oprogramowania opiera się na logice deterministycznej, w której te same dane wejściowe zawsze dają ten sam wynik. Natomiast uczenie maszynowe i testowanie muszą uwzględniać wyniki probabilistyczne, wynikające z ciągle zmieniających się danych i modeli. Zmiana ta wprowadza znaczną złożoność, ponieważ systemy ML mogą zachowywać się w nieprzewidywalny sposób w miarę ewolucji danych.
Doskonałym przykładem jest model ML stosowany w służbie zdrowia, który początkowo działa dobrze, ale nagle traci na dokładności w momencie zmiany danych demograficznych pacjentów — zjawisko to znane jest jako dryf danych. W przeciwieństwie do klasycznych aplikacji, uczenie maszynowe i testowanie muszą stale monitorować takie zmiany, aby zapewnić bezpieczeństwo i skuteczność.
Złożoność ta jest spotęgowana przez masowe wdrażanie ML w różnych branżach. Według Gartnera (2025) 90% przedsiębiorstw stosuje obecnie uczenie maszynowe w procesach o znaczeniu krytycznym. Otoczenie regulacyjne, takie jak unijna ustawa o sztucznej inteligencji, wymaga wyjaśnialności i rygorystycznej walidacji, co sprawia, że zgodność z przepisami staje się podstawową kwestią dla zespołów zajmujących się uczeniem maszynowym i testowaniem.
Rozwój MLOps jeszcze bardziej zintegrował zasady DevOps z cyklem życia ML. Testowanie jest obecnie ciągłym, zautomatyzowanym procesem wbudowanym w procesy rozwoju. Kompleksowy przegląd tych ewoluujących praktyk można znaleźć w Ultimate Guide to MLOps: Process, Maturity & Best Practices, który zawiera cenne informacje na temat tego, jak organizacje doskonalą swoje procesy uczenia maszynowego i testowania.
Jednak nadal istnieją wyjątkowe wyzwania:
- Zapewnienie wysokiej jakości danych pochodzących z różnych źródeł
- Wykrywanie i eliminowanie dryftu modelu
- Osiągnięcie powtarzalności wyników
Kwestie te podkreślają, dlaczego uczenie maszynowe i testowanie wymagają specjalistycznych strategii wykraczających poza możliwości tradycyjnej kontroli jakości oprogramowania.
Główne cele testowania ML w 2026 r.
Wraz z rosnącą złożonością uczenia maszynowego i testowania niezbędne jest określenie jasnych celów. Wczesne wykrywanie błędów ma kluczowe znaczenie dla zmniejszenia kosztów dalszych etapów i zapobiegania konieczności ponownej pracy. Solidne testowanie pomaga zapewnić dobre uogólnienie modeli, zachowanie sprawiedliwości i przestrzeganie standardów etycznych.
Niezawodność jest kolejnym kluczowym celem, zwłaszcza że kod, dane i modele często ulegają zmianom w środowiskach produkcyjnych. Uczenie maszynowe i testowanie muszą wspierać szybką iterację i innowacje, ale bez narażania bezpieczeństwa lub zgodności z przepisami.
Rozważmy rzeczywisty scenariusz: system rekomendacji internetowego sprzedawcy detalicznego ulega błędowi regresji po rutynowej aktualizacji. Sprzedaż spada, a zaufanie klientów maleje. Dzięki kompleksowym praktykom uczenia maszynowego i testowania, takim jak testy regresji i testy behawioralne, problemy te można wykryć i rozwiązać, zanim wpłyną one na działalność firmy.
Główne cele na rok 2026 obejmują:
- Wczesne wykrywanie i zapobieganie błędom
- Uogólnienie w różnych rozkładach danych
- Sprawiedliwość i zgodność z zasadami etycznymi
- Niezawodność podczas częstych aktualizacji
- Umożliwianie szybkich innowacji przy minimalnym ryzyku
Ostatecznie organizacje, które priorytetowo traktują zaawansowane praktyki uczenia maszynowego i testowania, zapewniają sobie długoterminowy sukces. W miarę ewolucji otoczenia inwestycje w solidną walidację, ciągłe monitorowanie i adaptacyjne frameworki testowe będą miały kluczowe znaczenie dla niezawodnych, skalowalnych systemów ML.
Rodzaje testów dla systemów uczenia maszynowego
Zrozumienie zakresu testów ma kluczowe znaczenie dla skutecznego uczenia maszynowego i testowania. Wraz ze wzrostem złożoności systemów ML zespoły muszą stosować połączenie tradycyjnych testów oprogramowania i podejść specyficznych dla ML. Zapewnia to solidność i niezawodność każdego komponentu, od kodu po dane i modele.
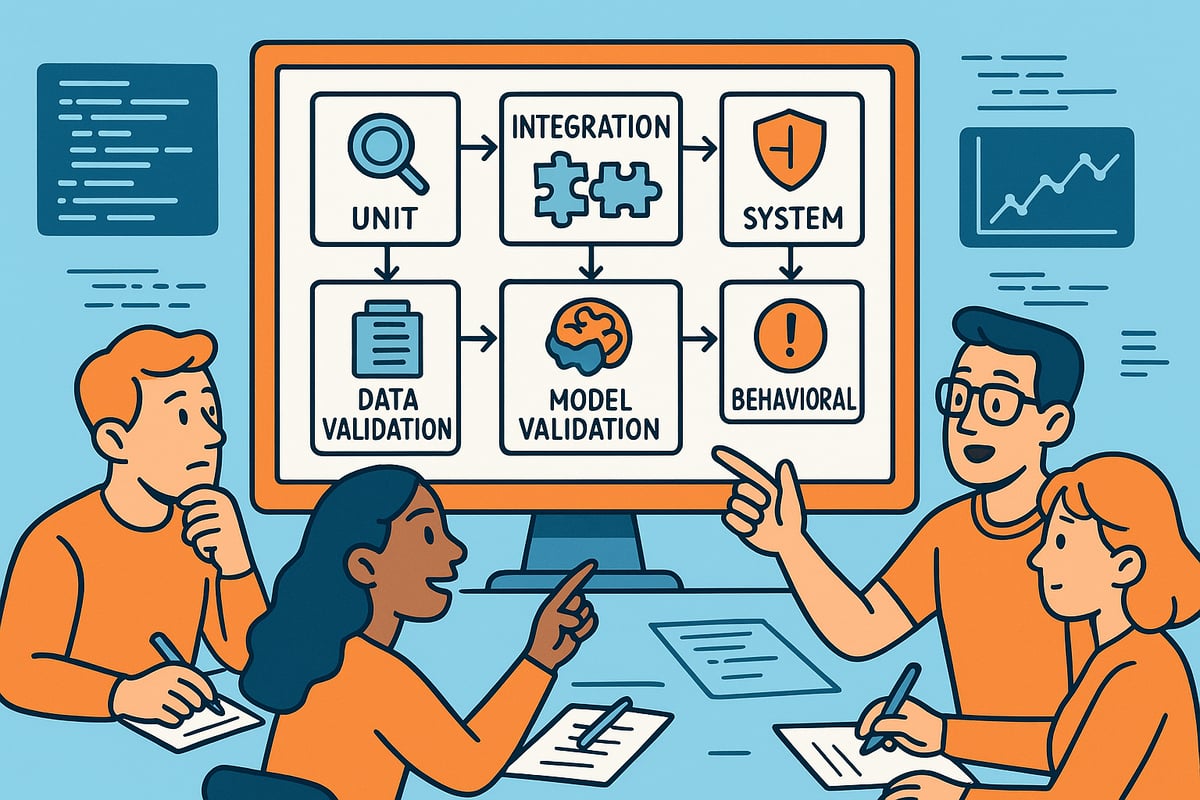
Testy jednostkowe, integracyjne, systemowe i akceptacyjne
Podstawą uczenia maszynowego i testowania są klasyczne rodzaje testów oprogramowania. Testy jednostkowe sprawdzają poszczególne funkcje lub komponenty kodu, takie jak metoda skalowania funkcji lub funkcja czyszczenia danych. Testy te pomagają wcześnie wykrywać błędy i budować zaufanie do izolowanej logiki.
Testy integracyjne zapewniają płynną współpracę wielu części potoku ML, takich jak przetwarzanie wstępne danych, inżynieria funkcji i wnioskowanie modelowe. Na przykład test integracyjny może wykryć niezgodność w schemacie danych, która w przeciwnym razie zakłóciłaby działanie potoku w czasie wykonywania.
Testy systemowe oceniają cały proces, od pozyskiwania surowych danych po obsługę modeli. Potwierdzają one, że cały proces uczenia maszynowego i testowania zapewnia oczekiwane wyniki w środowisku zbliżonym do produkcyjnego.
Testy akceptacyjne (lub testy użytkowników) sprawdzają, czy system spełnia wymagania biznesowe i normy regulacyjne. Testy te mogą sprawdzać, czy model wykrywania oszustw spełnia progi zgodności lub czy chatbot AI odpowiada poprawnie na zapytania użytkowników.
Testy regresji odgrywają istotną rolę w uczeniu maszynowym i testowaniu, zapewniając, że nowe zmiany nie powodują ponownego pojawienia się wcześniej naprawionych błędów. Na przykład po aktualizacji algorytmu rekomendacji testy regresji potwierdzają, że wcześniejsze problemy, takie jak powielające się sugestie, nie powracają.
Poniższa tabela podsumowuje, w jaki sposób każdy rodzaj testu wpisuje się w uczenie maszynowe i testowanie:
| Typ testu | Obszar zainteresowania | Typowy przykład |
|---|---|---|
| Jednostka | Funkcje kodu | Normalizacja funkcji testowej |
| Integracja | Elementy potoku | Wstępne przetwarzanie danych + wnioskowanie modelu |
| System | Kompleksowy przepływ pracy | Od surowych danych do generowania prognoz |
| Akceptacja | Biznes/regulacje | Zgodność z RODO |
| Regresja | Zapobieganie błędom | Zapobiega powtarzaniu się znanych problemów |
Prosty test jednostkowy funkcji skalowania może wyglądać następująco:
def test_scaling_negative():
assert scale(-5) == expected_output
Uczenie maszynowe i testowanie czerpią korzyści z tej podstawy, zapewniając wczesne wykrywanie błędów i wspierając szybką iterację. Aby uzyskać więcej informacji na temat tych zasad, zapoznaj się z przeglądem testowania oprogramowania i systemów.
Specjalistyczne podejścia do testowania ML
Oprócz klasycznych testów oprogramowania, uczenie maszynowe i testowanie wymagają specjalistycznych podejść, aby sprostać wyzwaniom związanym z danymi. Testy walidacji danych mają kluczowe znaczenie; sprawdzają one, czy dane wejściowe odpowiadają oczekiwanym typom, zakresom i rozkładom. Na przykład test może zasygnalizować, czy nagły wzrost brakujących wartości zagraża wiarygodności modelu.
Testy walidacji modelu oceniają dokładność, precyzję, przypomnienie i sprawiedliwość modelu. Testy te pomagają zespołom potwierdzić, że wyszkolony model dobrze uogólnia i nie wprowadza błędów systematycznych. Na przykład test walidacji modelu może ujawnić, czy nowa wersja modelu działa gorzej dla określonej grupy użytkowników.
Testy behawioralne symulują rzeczywiste scenariusze, aby zapewnić, że modele zachowują się zgodnie z oczekiwaniami w różnych warunkach. Na przykład testy te mogą wprowadzać rzadkie lub niekorzystne przykłady w celu zbadania stabilności modelu.
Testy statystyczne są niezbędne do wykrywania nadmiernego dopasowania, niedopasowania lub wycieku danych. Pomagają one utrzymać integralność modelu w czasie, zwłaszcza w przypadku wprowadzania nowych danych.
Oto kilka specjalistycznych rodzajów testów stosowanych w uczeniu maszynowym i testowaniu:
- Walidacja danych: sprawdzanie schematów, wykrywanie brakujących wartości, analiza rozkładu
- Walidacja modelu: wskaźniki wydajności, sprawiedliwość, sprawdzanie odporności
- Behawioralne: symulacja skrajnych przypadków, scenariusze danych wejściowych o charakterze antagonistycznym
- Statystyczne: wykrywanie dryftu, identyfikacja wycieków
Uczenie maszynowe i testowanie są najskuteczniejsze, gdy te specjalistyczne testy są zautomatyzowane i zintegrowane z procesami. Takie podejście zapewnia stałą jakość, zapobiega cichym awariom i wspiera zgodność z ewoluującymi standardami branżowymi.
Przewodnik krok po kroku dotyczący wdrażania najlepszych praktyk w zakresie testowania ML
Uczenie maszynowe i testowanie stały się nieodłącznymi elementami tworzenia niezawodnych systemów sztucznej inteligencji w 2026 roku. Stosowanie jasnego, ustrukturyzowanego podejścia pomaga zapewnić, że modele dostarczają wiarygodnych wyników, dostosowują się do zmian i są zgodne z przepisami. Przyjrzyjmy się temu procesowi krok po kroku.

Krok 1: Stworzenie ram i narzędzi testowych
Solidna podstawa ma kluczowe znaczenie dla skutecznego uczenia maszynowego i testowania. Zacznij od wybrania ram testowych, które pasują do Twojego stosu. Popularne wybory obejmują pytest, unittest i narzędzia specyficzne dla ML, takie jak Great Expectations. Zorganizuj swój projekt za pomocą dedykowanych katalogów dla testów obejmujących kod, dane i modele.
Zintegruj zestaw testów z potokami CI/CD, aby zautomatyzować wykrywanie i wykonywanie. Na przykład konfiguracja pytest może wykorzystywać fixtury i testy parametryczne w celu usprawnienia konfiguracji:
import pytest
@pytest.fixture
def sample_data():
return [1, 2, 3]
def test_sum(sample_data):
assert sum(sample_data) == 6
Aby uzyskać kompleksowy przegląd podstawowych zasad, warto zapoznać się z dokumentem MLOps Principles, który obejmuje podstawowe strategie dotyczące solidnego uczenia maszynowego i testowania.
Krok 2: Testowanie artefaktów kodu
Następnym punktem zainteresowania jest jakość kodu. Należy pisać atomowe funkcje i klasy o pojedynczej odpowiedzialności, aby ułatwić precyzyjne testowanie jednostkowe. Należy upewnić się, że wszystkie typy danych wejściowych i wyjściowych są sprawdzane, obsługiwać wyjątki i uwzględniać skrajne przypadki.
Utrzymuj centralne repozytorium modułów testowych wielokrotnego użytku. Takie podejście przyspiesza rozwój i zwiększa spójność między projektami. Na przykład test jednostkowy funkcji skalowania funkcji może wychwycić nieoczekiwane wartości ujemne, zapobiegając problemom na dalszych etapach.
- Sprawdź, czy wyniki funkcji mieszczą się w oczekiwanych zakresach.
- Przetestuj wyjątki przy użyciu nieprawidłowych danych wejściowych.
- Ponownie wykorzystuj wspólne narzędzia testowe w całym zespole.
Każda inicjatywa związana z uczeniem maszynowym i testowaniem korzysta z rygorystycznych, wielokrotnego użytku testów kodu.
Krok 3: Sprawdzanie jakości i integralności danych
Dane są podstawą uczenia maszynowego i testowania. Wprowadź kontrole schematu, aby upewnić się, że typy i struktury danych są zgodne z oczekiwaniami. Wykorzystaj kontrole zakresu wartości i wykrywanie wartości null, aby oznaczyć anomalie, zanim dotrą one do modelu.
Testy statystyczne mogą monitorować dryft danych lub nagłe anomalie. Zautomatyzuj te kontrole w swoich potokach pozyskiwania danych, aby problemy były wykrywane na wczesnym etapie. Na przykład gwałtowny wzrost liczby brakujących wartości może wywołać alerty i zapobiec pogorszeniu jakości modelu.
- Określ jasne oczekiwania dotyczące danych.
- Skonfiguruj automatyczne kontrole typowych problemów związanych z danymi.
- Zintegruj walidację z procesami przetwarzania danych.
Ciągła walidacja danych zapewnia niezawodność procesów uczenia maszynowego i testowania.
Krok 4: Testowanie artefaktów modelu
Testowanie modeli ma zasadnicze znaczenie dla utrzymania wydajności, sprawiedliwości i niezawodności. Wyniki modeli należy oceniać za pomocą wskaźników takich jak dokładność, precyzja, przypomnienie i sprawiedliwość. Testy regresji mają kluczowe znaczenie dla zapewnienia, że aktualizacje nie spowodują ponownego pojawienia się starych błędów lub tendencyjności.
Testy behawioralne symulują rzeczywiste i niekorzystne scenariusze, doprowadzając modele do granic możliwości. Na przykład przeprowadzenie testu regresji na modelu zatwierdzania kredytów może potwierdzić, że aktualizacje nie powodują nieumyślnego ponownego wprowadzenia stronniczości.
- Śledź wydajność modelu w czasie.
- Symuluj skrajne przypadki i niekorzystne dane wejściowe.
- Przechowuj historię wyników oceny modeli.
Dokładne testowanie artefaktów modelu jest kluczowym elementem uczenia maszynowego i sukcesu testowania.
Krok 5: Automatyzacja i integracja testowania w procesach uczenia maszynowego
Automatyzacja jest podstawą wydajnego uczenia maszynowego i testowania. Skonfiguruj automatyczne wykonywanie testów dla każdego zatwierdzenia kodu, zmiany danych lub aktualizacji modelu. Używaj narzędzi takich jak pre-commit hooks i GitHub Actions, aby zapewnić ciągłą walidację.
Monitoruj zakres testów i proaktywnie eliminuj wszelkie luki. Zautomatyzowane potoki mogą wykrywać błędy integracji przed wdrożeniem, zmniejszając ryzyko wystąpienia kosztownych problemów w produkcji.
- Zautomatyzuj testy na każdym etapie cyklu życia ML.
- Korzystaj z pulpitów nawigacyjnych, aby monitorować zakres i wyniki.
- Wyzwalaj alerty w przypadku nieudanych testów lub anomalii.
Automatyzacja zapewnia elastyczność i niezawodność procesów uczenia maszynowego i testowania.
Krok 6: Dokumentuj i utrzymuj zestawy testów
Dokumentacja stanowi podstawę trwałości praktyk uczenia maszynowego i testowania. Należy jasno dokumentować każdy przypadek testowy, w tym jego cel i oczekiwane wyniki. Testy należy regularnie aktualizować w miarę ewolucji danych i logiki modelu.
Śledź wyniki testów, awarie i zmiany w czasie. Dobrze utrzymana dokumentacja przyspiesza wdrażanie nowych pracowników i ciągłe doskonalenie. Na przykład, gdy do zespołu dołączają nowi członkowie, przejrzysta dokumentacja testów pomaga im szybko zrozumieć zasady testowania.
- Utrzymuj aktualną dokumentację przypadków testowych.
- Przeglądaj i poprawiaj testy przy każdej większej zmianie.
- Stosuj kontrolę wersji zarówno dla kodu, jak i artefaktów testowych.
Spójna dokumentacja jest ostatnim krokiem w procesie zapewnienia skalowalności i przyszłościowości praktyk związanych z uczeniem maszynowym i testowaniem.
Najlepsze praktyki dotyczące niezawodnych i skalowalnych testów ML
Budowanie niezawodnych i skalowalnych systemów jest podstawą udanych inicjatyw w zakresie uczenia maszynowego i testowania. W miarę jak modele i potoki danych stają się coraz bardziej złożone, stosowanie sprawdzonych najlepszych praktyk gwarantuje, że rozwiązania ML pozostają solidne, łatwe w utrzymaniu i gotowe do sprostania wymaganiom przedsiębiorstwa.

Zasady skutecznego testowania ML
Przestrzeganie rozsądnych zasad ma zasadnicze znaczenie dla skutecznego uczenia maszynowego i testowania. Poniższa tabela zawiera podsumowanie podstawowych praktyk, które powinien stosować każdy zespół ML:
| Zasada | Opis |
|---|---|
| Projekt atomowy | Funkcje i klasy powinny realizować jedno zadanie, aby testy były prostsze. |
| Kompozycja testów | Pisz nowe testy wraz z nowymi komponentami, aby zapewnić płynną integrację. |
| Możliwość ponownego wykorzystania | Scentralizuj logikę testów, aby zapewnić spójność i wydajność. |
| Zarządzanie regresją | Dodaj ukierunkowane testy dla każdego wykrytego błędu, aby zapobiec jego ponownemu wystąpieniu. |
| Wskaźniki pokrycia | Śledź pokrycie, ale unikaj nadmiernego dopasowywania testów do kodu źródłowego. |
| Automatyzacja | Zintegruj testy z CI/CD, aby zapewnić niezawodne egzekwowanie. |
Praktyczne podejście do uczenia maszynowego i testowania zaczyna się od napisania atomowego, łatwego do przetestowania kodu. Na przykład prosty test jednostkowy dla funkcji normalizacji w języku Python może wyglądać następująco:
def test_normalize_min_max():
data = [0, 50, 100]
result = normalize_min_max(data)
assert result == [0.0, 0.5, 1.0]
Automatyzacja zmienia zasady gry w zakresie uczenia maszynowego i testowania. Dzięki wbudowaniu wykonywania testów w przepływy pracy CI/CD można wcześnie wykrywać problemy i utrzymywać stałą jakość. Aby uzyskać więcej informacji na temat trendów w automatyzacji i zaawansowanych strategii MLOps, zapoznaj się z artykułem 5 najnowocześniejszych technik MLOps, na które warto zwrócić uwagę w 2026 r.
Pamiętaj, że solidne praktyki uczenia maszynowego i testowania mogą znacznie skrócić czas wdrażania nowych projektów i członków zespołu.
Typowe pułapki i sposoby ich uniknięcia
Pomimo najlepszych starań zespoły często napotykają pułapki, które podważają skuteczność uczenia maszynowego i testowania. Świadomość i proaktywne działania są kluczem do zapobiegania takim sytuacjom:
- Pominięcie walidacji danych może skutkować cichymi, kosztownymi awariami modelu.
- Zaniedbanie testów behawioralnych może spowodować, że skrajne przypadki pozostaną nierozwiązane.
- Poleganie na testach ręcznych spowalnia proces wydawania nowych wersji i zwiększa ryzyko przeoczenia.
- Nieaktualne zestawy testów nie odzwierciedlają zmieniających się danych lub logiki modelu, powodując fałszywe alarmy.
- Pominięcie testów regresji powoduje, że stare błędy pojawiają się ponownie po aktualizacjach.
Aby uniknąć tych pułapek, należy zautomatyzować walidację na każdym etapie, od potoków danych po wdrażanie modeli. Regularnie aktualizuj zestaw testów wraz ze zmianami modeli lub danych. Testy behawioralne i regresyjne powinny być priorytetem, a nie dodatkiem.
Dyscyplinarne podejście do uczenia maszynowego i testowania, skoncentrowane na ciągłym doskonaleniu, gwarantuje, że systemy ML zapewniają spójne, niezawodne wyniki, nawet w przypadku zmian wymagań.
Zaawansowane techniki i nowe trendy w testowaniu ML
Zaawansowane strategie uczenia maszynowego i testowania mają kluczowe znaczenie, ponieważ organizacje poszerzają granice wdrażania sztucznej inteligencji w 2026 r. Ponieważ modele mają wpływ na bardziej krytyczne decyzje biznesowe, zaawansowane techniki testowania zapewniają uczciwość, przejrzystość i odporność. Przyjrzyjmy się trzem nowym filarom kształtującym przyszłość uczenia maszynowego i testowania.
Testowanie pod kątem sprawiedliwości, stronniczości i wyjaśnialności
Zapewnienie sprawiedliwości i przejrzystości jest obecnie priorytetem dla specjalistów zajmujących się uczeniem maszynowym i testowaniem. Nowoczesne frameworki regularnie zawierają wskaźniki sprawiedliwości, takie jak parytet demograficzny i równe szanse, aby śledzić wyniki w wrażliwych grupach. Zautomatyzowane narzędzia do wykrywania stronniczości skanują dane i wyniki modeli w poszukiwaniu ukrytych uprzedzeń, pomagając zespołom spełniać wymogi regulacyjne i etyczne.
Równie istotna jest wyjaśnialność. Narzędzia takie jak SHAP i LIME zapewniają jasne, interpretowalne zestawienia sposobu podejmowania decyzji przez modele, wspierając zarówno zgodność z przepisami, jak i zaufanie interesariuszy. Na przykład audyt sprawiedliwości może ujawnić, że model rekrutacji faworyzuje jedną grupę demograficzną nad inną, co wymaga podjęcia natychmiastowych działań naprawczych.
Jeśli chcesz pogłębić swoją wiedzę na temat tych koncepcji, kurs „Podstawy uczenia maszynowego ” oferuje praktyczne informacje na temat sprawiedliwości i wyjaśnialności w nowoczesnych procesach uczenia maszynowego. Wdrożenie tych praktyk w procesach uczenia maszynowego i testowania pomaga organizacjom chronić się przed stronniczością i zachować przejrzystość.
Monitorowanie i testowanie w produkcji
Środowiska produkcyjne stawiają przed uczeniem maszynowym i testowaniem wyjątkowe wyzwania. Chociaż testy przed wdrożeniem pozwalają wykryć wiele problemów, rzeczywiste dane mogą nadal powodować nieprzewidziane problemy. Zespoły rozróżniają obecnie walidację offline od aktywnego monitorowania po wdrożeniu, aby zapewnić ciągłą niezawodność modelu.
Zaawansowane systemy monitorowania śledzą dryft danych, dryft modeli i nieoczekiwane spadki wydajności. Automatyczne wyzwalacze mogą cofać wdrożenia lub uruchamiać ponowne szkolenia, gdy wskaźniki wykraczają poza bezpieczne zakresy. Na przykład, gdy model produkcyjny wykrywa zmianę w zachowaniu klientów, automatyczne alerty nakłaniają zespół do zbadania sytuacji i ponownego przeszkolenia w razie potrzeby.
Takie proaktywne podejście do uczenia maszynowego i testowania zapewnia, że modele pozostają solidne, dokładne i zgodne z celami biznesowymi. Konsekwentne monitorowanie i szybka reakcja są obecnie standardem w przypadku systemów ML o wysokiej stawce, działających w rzeczywistym świecie.
Przyszłe trendy: testowanie wspomagane sztuczną inteligencją i systemy samonaprawiające się
Przyszłość uczenia maszynowego i testowania szybko się zmienia. Narzędzia oparte na sztucznej inteligencji mogą teraz generować przypadki testowe, odkrywając skrajne scenariusze, które mogą umknąć testerom ręcznym. Systemy te wykorzystują wykrywanie anomalii do sygnalizowania subtelnych problemów w ogromnych zbiorach danych, umożliwiając bardziej wyczerpującą walidację.
Pojawiają się samonaprawiające się systemy ML, które są w stanie automatycznie korygować lub ostrzegać zespoły w przypadku wystąpienia błędów testowych w produkcji. Zmiana ta napędza integrację testowania z zarządzaniem modelami i procesami zapewniania zgodności, zapewniając identyfikowalność i możliwość audytu na dużą skalę.
Dla liderów inżynierii zrozumienie tych trendów ma kluczowe znaczenie. 10 najlepszych praktyk MLOps dla liderów inżynierii w 2025 r. zawiera praktyczne strategie wdrażania solidnych procesów uczenia maszynowego i testowania. Wykorzystanie testów wspomaganych sztuczną inteligencją i funkcji samonaprawy pozwala organizacjom osiągnąć doskonałość w zakresie niezawodności i innowacyjności.
Studia przypadków i przykłady z życia wzięte
W różnych branżach uczenie maszynowe i testowanie okazują się niezbędne dla odporności biznesowej i innowacyjności. Prawdziwe historie pokazują, jak organizacje zmieniają swoje wyniki, inwestując w kompleksowe frameworki testowe.
Wnioski od liderów branży
Liderzy branży pokazują, że solidne praktyki w zakresie uczenia maszynowego i testowania mogą bezpośrednio poprawić wydajność, niezawodność i zgodność z przepisami. Na przykład duża platforma e-commerce wdrożyła wielopoziomową strategię testowania ML, co doprowadziło do 60% redukcji przestojów systemu. Zespół skupił się na automatyzacji testów regresji i integracji, zapewniając weryfikację zmian w kodzie, danych i modelach przed każdym wydaniem.
Wiodąca instytucja finansowa stanęła w obliczu kosztownych błędów prognoz spowodowanych niewykrytymi odchyleniami danych. Dzięki wdrożeniu automatycznych testów regresji i integracji ciągłych kontroli walidacji danych nie tylko zapobiegła utracie przychodów, ale także zwiększyła zaufanie do swoich usług opartych na sztucznej inteligencji. W tym kontekście inwestycja w kompleksowe potoki danych, zgodnie z tym, czego uczy się na kursie mistrzowskim z zakresu inżynierii danych i uczenia maszynowego, może znacznie wzmocnić procesy testowania i integracji.
Start-up zajmujący się sztuczną inteligencją w służbie zdrowia musiał spełniać surowe wymogi audytów regulacyjnych. Wykorzystał testy behawioralne do symulacji rzeczywistych scenariuszy pacjentów, zapewniając niezawodność swoich modeli diagnostycznych w różnych warunkach. Te studia przypadków ilustrują, w jaki sposób uczenie maszynowe i testowanie mogą pomóc organizacjom uniknąć kosztownych awarii i spełnić wysokie standardy.
Wyniki ilościowe
Wyniki dojrzałego wdrożenia uczenia maszynowego i testowania są wymierne. Według Forrester (2025) firmy stosujące zautomatyzowane testy ML odnotowują o 30% szybsze cykle wdrażania. Ponadto organizacje wykorzystujące narzędzia do walidacji danych i monitorowania odnotowały 70% spadek awarii modeli po wdrożeniu.
| Wskaźnik | Wpływ |
|---|---|
| Szybkość wdrażania | 30% szybsze dzięki automatyzacji |
| Awarie modelu po wdrożeniu | 70% redukcja |
| Skargi klientów (usługi oparte na sztucznej inteligencji) | 40% mniej po przeprowadzeniu solidnych testów |
Na przykład integracja testów behawioralnych i regresyjnych doprowadziła do zmniejszenia liczby skarg klientów dotyczących usług opartych na sztucznej inteligencji o 40%. Te ilościowe wyniki potwierdzają, że uczenie maszynowe i testowanie to nie tylko najlepsze praktyki, ale także kluczowe czynniki sukcesu biznesowego i niezawodności.
Jak widać, opanowanie testowania uczenia maszynowego jest niezbędne do budowania niezawodnych, etycznych i skalowalnych systemów AI w 2026 roku. Niezależnie od tego, czy chcesz usprawnić przepływ pracy w swojej organizacji, czy rozwinąć własne umiejętności, odpowiednie podstawy mają ogromne znaczenie. Jeśli jesteś gotowy, aby przekształcić najlepsze praktyki w rzeczywiste wyniki i wyróżnić się w szybko zmieniającej się dziedzinie sztucznej inteligencji, dlaczego nie zrobić kolejnego kroku? Już dziś możesz rozpocząć swoją przygodę i zostać certyfikowanym specjalistą AI Foundation. Zacznij za darmo.