AI and machine learning are experiencing explosive growth in 2026, with organizations worldwide racing to innovate faster than ever before. At the heart of this revolution, the right gpu for ai training is now more essential than ever, enabling breakthroughs in model accuracy and speed.
This article uncovers the top 7 essential GPUs for AI training, providing a detailed comparison of their features, performance, and overall value. You will discover cutting-edge options from industry leaders, each designed to solve unique challenges faced by professionals and organizations.
We will highlight what sets each gpu for ai training apart, from memory bandwidth to ecosystem support, so you can make informed decisions that directly impact your AI training outcomes. Ready to find the perfect fit for your next breakthrough? Let’s explore the best options on the market.
Why the Right GPU Matters for AI Training in 2026
Selecting the right gpu for ai training is crucial as AI models in 2026 are larger and more complex than ever. The demands on hardware have skyrocketed, making GPU choice a pivotal decision for research labs, startups, and enterprises alike.
AI Model Complexity and GPU Demands
The scale of AI models in 2026 has grown exponentially, with billion-parameter language models and multi-modal architectures now commonplace. These advancements push the limits of hardware, requiring a gpu for ai training that can handle massive parallel processing and high data throughput.
Modern GPUs offer specialized tensor cores, high-bandwidth memory, and support for advanced floating point operations. According to AI model complexity and GPU demands statistics 2026, state-of-the-art GPUs can reduce training times by up to 60% compared to previous generations, enabling faster prototyping and deployment.
Choosing a gpu for ai training that matches your model's complexity is essential for maximizing efficiency and keeping pace with industry innovation.
Cost, Scalability, and ROI Considerations
The financial impact of choosing a gpu for ai training is significant. Upfront costs can be substantial, especially for enterprise-grade GPUs, but operational savings and increased productivity often justify the investment.
Organizations must weigh the price of premium GPUs against potential cost savings from reduced training times and improved scalability. Many find that investing in high-performance GPUs pays off through faster time-to-market and better model accuracy.
Scalable solutions, such as multi-GPU clusters or cloud-based platforms, allow teams to flexibly manage workloads and optimize spending. A well-chosen gpu for ai training can transform ROI, making advanced AI accessible to organizations of all sizes.
Power Efficiency and Sustainability
As AI adoption grows, so does the need for sustainable infrastructure. The latest gpu for ai training options prioritize energy efficiency, featuring redesigned architectures that lower power consumption without sacrificing performance.
Power-efficient GPUs not only reduce operational costs but also help organizations meet environmental goals. New models demonstrate significant drops in energy usage per training run, contributing to a smaller carbon footprint.
Sustainability is now a core factor in GPU selection. By investing in an efficient gpu for ai training, organizations can align technology strategy with green initiatives, supporting both business and environmental objectives.
Compatibility and Ecosystem Support
For seamless AI development, a gpu for ai training must integrate smoothly with popular frameworks like TensorFlow and PyTorch. Mature driver support and a robust software ecosystem are key for maximizing hardware utilization.
Modern GPUs are designed for flexibility, supporting on-premise, cloud, and hybrid deployments. This versatility ensures organizations can adapt to changing project needs without overhauling infrastructure.
Additionally, leading GPUs offer extensive documentation, community support, and optimized libraries, enabling developers to unlock full performance potential. Choosing a gpu for ai training with strong ecosystem backing ensures long-term productivity and innovation.
7 Essential GPU for AI Training Options in 2026
Selecting the right gpu for ai training is more crucial than ever in 2026. Professionals and organizations face a rapidly evolving landscape, with new hardware pushing the limits of speed, capacity, and efficiency. Below, we break down the top 7 essential options for every scale and scenario.
NVIDIA H200 Tensor Core GPU
The NVIDIA H200 Tensor Core GPU sets a new standard for gpu for ai training. With Hopper architecture and up to 141GB HBM3e memory, it delivers up to 4.8TB/s bandwidth and exceptional 32-bit floating point performance.
Pricing: Estimated $35,000+, varying by configuration and vendor.
Core Features:
- Hopper architecture
- Up to 141GB HBM3e memory
- 4.8TB/s memory bandwidth
- PCIe Gen 5 support
Benefits:
This gpu for ai training provides unmatched throughput, especially for large language models and generative AI. Its robust software ecosystem and advanced security features make it a favorite among research labs and cloud providers.
Target Audience:
AI research labs, enterprises training massive models, cloud service providers.
Pros:
- Industry-leading performance for gpu for ai training
- Deep integration with AI frameworks
- Advanced hardware security
Cons:
- High acquisition cost
- Requires advanced cooling and infrastructure
Example:
Used in top cloud AI supercomputers powering billion-parameter model training.
AMD Instinct MI300X
AMD’s Instinct MI300X is a formidable gpu for ai training, offering up to 192GB HBM3 memory and 5.2TB/s bandwidth, built on the CDNA 3 architecture.
Pricing: Estimated $15,000–$20,000.
Core Features:
- CDNA 3 architecture
- Up to 192GB HBM3 memory
- 5.2TB/s bandwidth
- Optimized for FP16/BF16 workloads
Benefits:
This gpu for ai training excels in memory-intensive deep learning and inference, supporting massive model sizes with ease.
Target Audience:
Enterprises and cloud providers needing high memory for large-scale AI applications.
Pros:
- Exceptional memory capacity
- Strong price-to-performance ratio
- Open ROCm ecosystem
Cons:
- Software ecosystem smaller than NVIDIA
- Some compatibility considerations
Example:
Deployed in hyperscale data centers for multi-modal AI training and inference at scale.
Google Cloud TPU v5p
Google Cloud TPU v5p offers an elastic, cloud-based gpu for ai training experience. With 8,192 cores per pod and 2.4 PFLOPS per pod, it’s designed for rapid scaling.
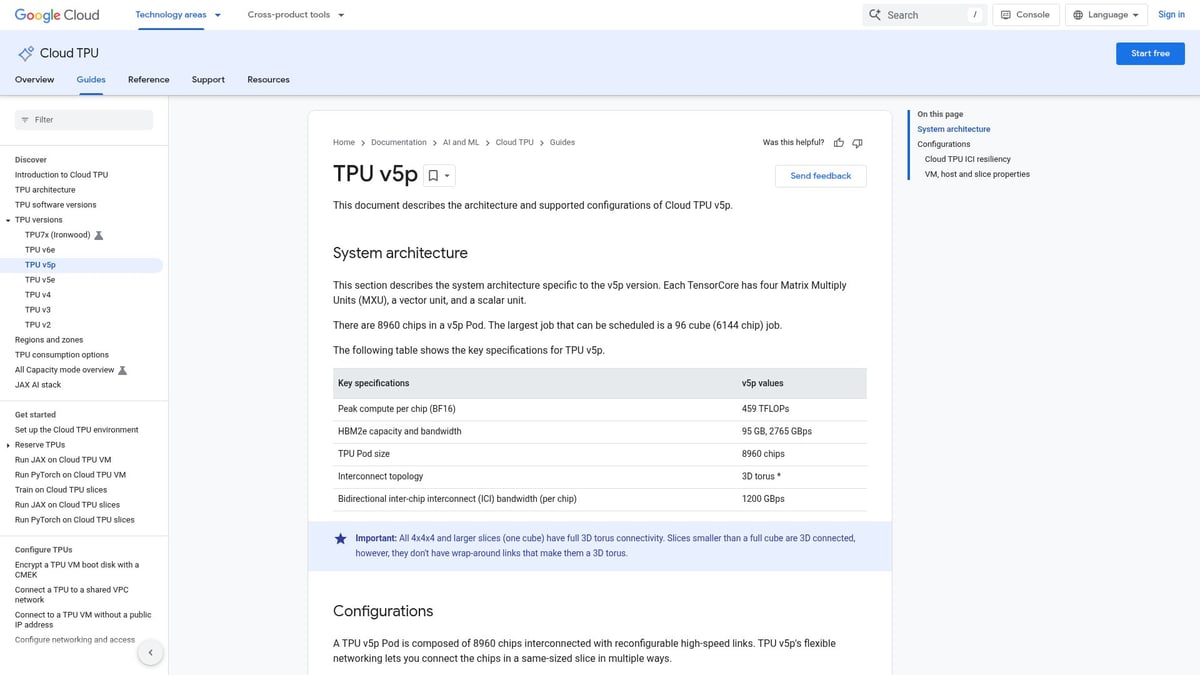
Pricing: Pay-as-you-go, starting at ~$8.00/hour.
Core Features:
- Custom AI accelerator
- 8,192 cores per pod
- 2.4 PFLOPS per pod
- Optimized for TensorFlow
Benefits:
This gpu for ai training enables seamless integration with Google Cloud and rapid scaling for large models, reducing time-to-insight.
Target Audience:
Researchers, startups, and enterprises needing flexible, elastic AI compute.
Pros:
- No hardware maintenance
- Instant scalability
- Tight integration with Google AI stack
Cons:
- Limited to cloud deployment
- Less flexibility for custom hardware setups
Example:
Used by Google DeepMind for advanced AI research in NLP and reinforcement learning.
Intel Gaudi 3 AI Accelerator
Intel’s Gaudi 3 AI Accelerator is a cost-efficient gpu for ai training, designed to maximize performance-per-dollar for deep learning workloads.
Pricing: Not publicly disclosed, but competitive with enterprise GPUs.
Core Features:
- 128GB HBM2e memory
- 1.8TB/s bandwidth
- Optimized for deep learning training and inference
Benefits:
This gpu for ai training offers lower total cost of ownership and leverages an open software stack (SynapseAI), making it ideal for organizations seeking cost-effective AI infrastructure.
Target Audience:
Enterprises optimizing for cost and open-source frameworks.
Pros:
- Cost-effective for gpu for ai training
- Open ecosystem and SynapseAI support
- Energy efficiency
Cons:
- Smaller developer community
- Newer entrant in the market
Example:
Adopted by AI startups for affordable, scalable model training and inference.
NVIDIA RTX 5090 (Ada Lovelace-Next)
The NVIDIA RTX 5090 brings next-gen Ada Lovelace architecture to the gpu for ai training landscape, with 32GB GDDR7 memory and advanced tensor cores.
Pricing: Expected $2,000–$2,500.
Core Features:
- Ada Lovelace-Next architecture
- 32GB GDDR7 memory
- Advanced tensor cores
- PCIe Gen 5
Benefits:
Ideal for high-end workstations, this gpu for ai training is perfect for prototyping and small-scale model development.
Target Audience:
AI developers, small teams, universities, creative professionals.
Pros:
- Affordable for individuals and small teams
- Strong software support
- High clock speeds
Cons:
- Not optimized for hyperscale workloads
- Limited memory for the largest models
Example:
Frequently used by AI startups and academic labs for rapid experimentation and proof-of-concept work.
AWS Trainium2 Accelerator
AWS Trainium2 is a purpose-built gpu for ai training, available exclusively via Amazon Web Services. It provides up to twice the performance of previous models and integrates seamlessly with AWS SageMaker.
Pricing: On-demand, typically $4–$7/hour per instance.
Core Features:
- Custom silicon for AI training
- Up to 2x performance boost
- AWS SageMaker integration
Benefits:
This gpu for ai training offers elastic scaling and pay-as-you-go flexibility, making it ideal for distributed AI training pipelines.
Target Audience:
Enterprises and developers building on AWS cloud.
Pros:
- No upfront hardware investment
- Seamless AWS ecosystem integration
- High throughput for deep learning
Cons:
- Cloud-only deployment
- Dependent on AWS service availability
Example:
Adopted by Fortune 500 companies for large-scale, distributed AI training.
Mammoth Club: AI Training Platform
Mammoth Club stands out not as a physical gpu for ai training, but as a comprehensive learning and upskilling platform for professionals and organizations.
Pricing: Premium Club Membership $199 (limited time), regular $1,999. Custom pricing for teams.
Core Features:
- 3,000+ AI and technology courses
- Personalized AI-powered learning
- Interactive bootcamps and certification programs
Benefits:
Empowers users to master gpu for ai training, stay current with industry trends, and maximize their hardware ROI through continuous learning.
Target Audience:
Individuals and organizations aiming to upskill in AI, data science, and advanced GPU use.
Pros:
- Unlimited course access
- Industry-recognized certifications
- Adaptive learning and practice resources
Cons:
- Does not provide physical GPU hardware
- Focused on training and knowledge
Example:
Utilized by tech teams and enterprises to build AI expertise and optimize GPU utilization.
Quick Comparison Table
| GPU/Platform | Memory | Bandwidth | Price (Est.) | Best For |
|---|---|---|---|---|
| NVIDIA H200 | 141GB HBM3e | 4.8TB/s | $35,000+ | Supercomputing, LLMs |
| AMD MI300X | 192GB HBM3 | 5.2TB/s | $15,000–$20,000 | High-memory deep learning |
| Google Cloud TPU v5p | N/A | N/A | ~$8/hr (cloud) | Elastic cloud AI |
| Intel Gaudi 3 | 128GB HBM2e | 1.8TB/s | Competitive | Cost-efficient, open frameworks |
| NVIDIA RTX 5090 | 32GB GDDR7 | N/A | $2,000–$2,500 | Workstations, prototyping |
| AWS Trainium2 | N/A | N/A | $4–$7/hr (cloud) | Distributed cloud AI |
| Mammoth Club | N/A | N/A | $199–$1,999 | Upskilling, AI training knowledge |
For a detailed side-by-side review of real-world performance and benchmarks, explore the latest AI training GPU performance benchmarks 2026, which provides up-to-date metrics and pricing for each gpu for ai training featured here.
Choosing the right gpu for ai training involves balancing performance, memory, scalability, and ecosystem support. Whether you need raw power, flexibility, or skill development, these seven options represent the leading edge for AI professionals and organizations in 2026.
Key Factors to Consider When Choosing a GPU for AI Training
Selecting the right gpu for ai training is crucial for achieving optimal results in 2026. As AI models and workloads evolve, professionals must weigh multiple factors, from raw performance to software compatibility and future-proofing. Understanding these key considerations will empower you to make informed investments that align with your specific AI training needs.
Performance Metrics: FLOPS, Memory, and Bandwidth
When evaluating a gpu for ai training, three core metrics stand out: floating point operations per second (FLOPS), video RAM (VRAM), and memory bandwidth. FLOPS indicate the raw computational power, essential for high-speed matrix multiplications in deep learning.
VRAM determines how large a model or batch size you can fit on a single GPU, directly impacting training efficiency. Memory bandwidth affects how quickly data moves between memory and compute cores, influencing throughput for data-intensive workloads.
For example, a comparison table of recent GPUs shows how these factors vary:
| GPU Model | FLOPS (TFLOPS) | VRAM (GB) | Bandwidth (TB/s) |
|---|---|---|---|
| NVIDIA H200 | 1970 | 141 | 4.8 |
| AMD MI300X | 1460 | 192 | 5.2 |
Choosing a gpu for ai training with higher values in these areas can drastically cut training times.
Software Ecosystem and Framework Support
A robust software ecosystem is vital when selecting a gpu for ai training. Leading frameworks like TensorFlow, PyTorch, and JAX require mature drivers and optimized libraries to fully utilize hardware capabilities.
Key libraries such as cuDNN (NVIDIA) and ROCm (AMD) offer deep integration with AI frameworks, enhancing performance and stability. Broad community support ensures timely updates, bug fixes, and compatibility with the latest models.
For instance, NVIDIA GPUs benefit from a long-standing, mature stack and extensive documentation. AMD and Intel have made significant strides, but some users may encounter compatibility challenges with niche tools. Ensuring your gpu for ai training aligns with your preferred frameworks minimizes integration issues and maximizes productivity.
Scalability and Multi-GPU Configurations
For complex projects, scalability is a top concern when choosing a gpu for ai training. Technologies like NVLink, PCIe Gen 5, and GPU clustering allow seamless multi-GPU setups, enabling both vertical (within a server) and horizontal (across servers) scaling.
Multi-GPU configurations boost parallelism, allowing you to train larger models or datasets faster. Enterprises often deploy clusters of GPUs to handle billion-parameter models, using advanced interconnects for low-latency communication.
Considerations include hardware compatibility, software support for distributed training, and ease of management. Selecting a scalable gpu for ai training setup ensures your infrastructure can grow alongside your AI ambitions.
Budget, Availability, and Future-Proofing
Balancing performance with cost is essential in the gpu for ai training decision process. Price-to-performance ratios vary widely across models and vendors, and market dynamics can impact availability. Supply chain fluctuations may cause delays or price hikes.
Evaluating total cost of ownership, including power and maintenance, is key. According to AI hardware cost and resource requirements analysis, understanding both upfront and ongoing expenses helps organizations maximize ROI.
To future-proof your gpu for ai training investment, consider hardware roadmaps and emerging standards. Opt for GPUs that support the latest interconnects and AI frameworks, ensuring longevity and adaptability as AI technology evolves.
Trends Shaping the Future of AI Training Hardware
The landscape for gpu for ai training is evolving rapidly, driven by innovation and demand for scalable, efficient solutions. Understanding these trends is essential for organizations and professionals aiming to stay ahead in the AI race.
Specialized AI Accelerators and Custom Chips
A defining trend in gpu for ai training is the rise of specialized accelerators, including TPUs and custom silicon from major cloud providers. Companies like Google and AWS are investing in chips tailored for deep learning, boosting efficiency and reducing costs. These domain-specific processors are optimized for parallel workloads and high throughput, making them attractive for large-scale AI deployments.
According to the AI data center GPU market growth forecast, the global market for AI GPUs and accelerators is set to surge through 2035. This growth is fueled by enterprises seeking to accelerate training times while controlling expenses. As more entrants develop custom chips, the diversity of options for gpu for ai training will continue to expand.
Energy Efficiency and Green AI
Sustainability is now a top priority in gpu for ai training. Hardware manufacturers are designing GPUs with advanced cooling, lower power draw, and smarter resource management. These improvements help organizations meet environmental goals and reduce operational costs.
Modern architectures utilize smaller process nodes, dynamic voltage scaling, and AI-driven workload optimization. Data shows that new GPU models can cut energy consumption per training run by up to 30 percent compared to previous generations. As regulations and public expectations grow, energy-efficient gpu for ai training solutions will be essential for responsible AI development.
Cloud vs. On-Premise vs. Hybrid Deployments
Deployment strategies for gpu for ai training are becoming more flexible. Many organizations leverage cloud-based GPUs for on-demand scalability, avoiding upfront capital expenses. On-premise solutions, meanwhile, offer greater control, data security, and potentially lower long-term costs for continuous workloads.
Hybrid approaches are gaining traction, allowing teams to balance rapid prototyping in the cloud with dedicated in-house infrastructure for sensitive projects. Enterprises and research labs are adopting multi-cloud and hybrid models to ensure redundancy and optimize resource allocation. Choosing the right deployment model is a strategic decision that shapes the effectiveness of gpu for ai training.
Open Source and Ecosystem Expansion
Open-source initiatives are transforming the gpu for ai training ecosystem. Platforms like ROCm and SynapseAI are driving innovation, lowering barriers to entry, and enabling broader hardware compatibility. This shift empowers developers to tailor solutions, share benchmarks, and accelerate adoption of new technologies.
Community-driven projects foster rapid iteration and transparency. As open-source software and hardware mature, organizations benefit from increased flexibility, reduced vendor lock-in, and enhanced collaboration. The expansion of open ecosystems will continue to be a catalyst for progress in gpu for ai training.
How to Maximize Your AI Training Investment in 2026
Investing in the right gpu for ai training is only the first step. To achieve long-term success, organizations must adopt strategies that optimize both budget and performance. Whether you are a startup, SMB, or large enterprise, a thoughtful approach ensures you extract the most value from your hardware.
Training Strategies for Different Budgets
Selecting the best gpu for ai training depends on your resources and project size. Startups and small teams often benefit from cloud-based GPUs, which offer flexibility without hefty upfront costs. For instance, leveraging pay-as-you-go services lets you scale compute power as needed.
Mid-sized businesses may consider a mix of cloud and on-premise GPUs, balancing operational expenses and control. Enterprises often invest in dedicated clusters for maximum throughput and data security. Here is a quick comparison:
| Budget | Strategy | Example GPU Options |
|---|---|---|
| Startup | Cloud-based, pay-per-use | AWS Trainium2, TPU v5p |
| SMB | Hybrid, shared resources | RTX 5090, MI300X |
| Enterprise | Dedicated clusters | H200, Gaudi 3 |
Evaluating your workflow and scaling needs helps you choose the most cost-effective gpu for ai training.
Leveraging AI Training Platforms and Courses
Continuous learning is vital for teams using advanced gpu for ai training. Upskilling not only improves model outcomes but also ensures you maximize hardware ROI. Platforms offering specialized courses and certifications empower individuals to master new frameworks and optimization techniques.
For those seeking a comprehensive program, the Data engineering and machine learning masterclass covers practical workflows directly related to GPU utilization. Understanding how to build efficient pipelines and manage large datasets can dramatically improve your productivity.
Encourage your team to pursue industry-recognized certifications. Investing in education ensures you stay ahead in the fast-evolving world of gpu for ai training.
Monitoring, Optimization, and Maintenance
To protect your investment in gpu for ai training, implement robust monitoring and optimization practices. Use performance tracking tools to analyze GPU utilization, memory consumption, and thermal metrics. This data helps identify bottlenecks and informs decisions to scale resources or tweak models.
Regularly update drivers and firmware to benefit from the latest performance enhancements. Employ best practices such as mixed-precision training and efficient data loading to extend hardware lifespan and reduce costs.
Proactive maintenance, combined with intelligent optimization, leads to higher throughput and a better return on your gpu for ai training investment.
Preparing for Next-Gen AI Hardware
Future-proofing your infrastructure is crucial as gpu for ai training technologies rapidly evolve. Stay informed about hardware roadmaps and upcoming releases from industry leaders. Subscribe to vendor updates and participate in community forums for the latest insights.
Design workflows that can adapt to new architectures with minimal disruption. Adopt containerization and modular software stacks, making it easier to upgrade or switch GPUs as new options emerge.
By planning ahead, you ensure your gpu for ai training setup remains competitive and ready for tomorrow's challenges.
As you explore the evolving landscape of AI training hardware and see just how much the right GPU can accelerate your projects, it becomes clear that staying ahead means continually building your expertise. Whether you’re optimizing for performance, efficiency, or value, having a strong foundation in AI is key to making smart choices and leading successful initiatives. If you’re ready to deepen your skills and earn industry-recognized credentials, I encourage you to Become a certified AI Foundation Specilaist. Start for free. Let’s take your AI journey to the next level together.