Die Revolution der künstlichen Intelligenz hängt von einem entscheidenden Faktor ab: der Rechenleistung. Während Unternehmen darum wetteifern, KI-Lösungen in ihren gesamten Betriebsabläufen zu implementieren, hat sich NVIDIA als unangefochtener Marktführer bei der Bereitstellung der Hardware- und Software-Infrastruktur etabliert, die fortschrittliches maschinelles Lernen ermöglicht. Das Verständnis der Grundlagen des KI-Trainings bei NVIDIA ist für jeden Fachmann und jedes Unternehmen, das künstliche Intelligenz effektiv nutzen möchte, unverzichtbar geworden. Von kleinen Start-ups bis hin zu Fortune-500-Unternehmen – die Fähigkeit, komplexe KI-Modelle schnell und effizient zu trainieren, entscheidet in der heutigen digitalen Wirtschaft über den Wettbewerbsvorteil.
Die Rolle von NVIDIA in der KI-Trainingsinfrastruktur verstehen
Die Dominanz von NVIDIA im Bereich der künstlichen Intelligenz reicht weit über die Herstellung von Grafikprozessoren hinaus. Das Unternehmen hat ein ganzes Ökosystem geschaffen, das speziell für Machine-Learning-Workloads konzipiert ist und modernste Hardware mit optimierten Software-Frameworks kombiniert, die den Trainingsprozess drastisch beschleunigen.
GPU-Architektur für Machine-Learning-Anwendungen
Die Grundlage für das NVIDIA-KI-Training bilden die spezialisierten GPU-Architekturen von NVIDIA. Im Gegensatz zu herkömmlichen Zentralprozessoren, die Aufgaben sequenziell abarbeiten, führen GPUs Tausende von Berechnungen gleichzeitig parallel durch. Diese Fähigkeit zur parallelen Verarbeitung erweist sich als unverzichtbar für das Training neuronaler Netze, das Millionen von Matrixmultiplikationen und Tensoroperationen erfordert.
Die neueste Blackwell-Architektur von NVIDIA stellt einen Quantensprung in der KI-Trainingsleistung dar. Laut den MLPerf Training v5.0-Benchmark-Ergebnissen von NVIDIA liefert die neue Architektur beispiellose Geschwindigkeitssteigerungen bei verschiedenen KI-Workloads. Die Architektur führt mehrere wichtige Innovationen ein:
- Verbesserte Tensor-Kerne, die für Berechnungen mit gemischter Genauigkeit optimiert sind
- Erhöhte Speicherbandbreite zur Beseitigung von Engpässen bei der Datenübertragung
- Fortschrittliche Multi-Instance-GPU-Technologie zur Isolierung von Workloads
- Verbesserte Energieeffizienz für nachhaltige groß angelegte Implementierungen
Für Fachleute, die sich mit KI-Hardwareoptionen befassen, ist das Verständnis dieser architektonischen Fortschritte hilfreich, um fundierte Infrastrukturentscheidungen zu treffen. Viele Unternehmen beginnen ihre KI-Reise damit, die richtige GPU für das KI-Training auszuwählen – basierend auf ihren spezifischen Workload-Anforderungen und Budgetvorgaben.
Software-Frameworks und Tools für das NVIDIA-KI-Training
Hardware allein reicht nicht aus, um eine optimale KI-Trainingsleistung zu erzielen. NVIDIA hat erheblich in die Entwicklung umfassender Software-Stacks investiert, die die GPU-Auslastung maximieren und den Entwicklungsprozess für Datenwissenschaftler und Machine-Learning-Ingenieure vereinfachen.
Grundlagen von CUDA und cuDNN
CUDA (Compute Unified Device Architecture) dient als grundlegendes Programmiermodell für NVIDIA-GPUs. Diese Plattform für paralleles Rechnen ermöglicht es Entwicklern, die Leistung der GPU für allgemeine Rechenaufgaben zu nutzen. Die cuDNN-Bibliothek baut auf CUDA auf und stellt hochoptimierte Primitive speziell für tiefe neuronale Netze bereit.
Diese grundlegenden Technologien ermöglichen:
- Beschleunigte lineare Algebra-Operationen durch optimierte BLAS-Bibliotheken
- Effiziente Faltungsalgorithmen für Anwendungenim Bereich Computer Vision
- Optimierte Implementierungen rekurrenter Netzwerke für die Verarbeitung natürlicher Sprache
- Schnelle Normalisierungs- und Aktivierungsfunktionen über alle Netzwerkschichten hinweg
- Speichereffiziente Trainingstechniken für größere Modellarchitekturen
Framework-Integration und -Optimierung
Beliebte Machine-Learning-Frameworks nutzen den Software-Stack von NVIDIA, um eine außergewöhnliche Leistung zu erzielen. TensorFlow, PyTorch und JAX bieten alle native CUDA-Unterstützung, sodass Entwickler frameworkunabhängigen Code schreiben können, der automatisch von der GPU-Beschleunigung profitiert.
| Framework | NVIDIA-Integration | Hauptanwendungsfälle | Leistungsvorteile |
|---|---|---|---|
| PyTorch | Native CUDA-Unterstützung | Forschung, Prototypenentwicklung | Dynamische Berechnungsgraphen |
| TensorFlow | XLA-Kompilierung | Produktive Bereitstellung | Graph-Optimierung |
| JAX | GPU-native Operationen | Wissenschaftliches Rechnen | Automatische Differenzierung |
| MXNet | Gluon-API | Skalierbares Training | Hybride Programmierung |
Das NVIDIA NeMo-Framework veranschaulicht diesen Integrationsansatz und bietet eine Open-Source-Pipeline, die speziell für das Training von Video-Grundmodellen bei optimaler GPU-Auslastung entwickelt wurde.
KI-Trainingsstrategien für Unternehmen mit NVIDIA-Technologie
Unternehmen, die KI-Trainings mit NVIDIA-Technologie implementieren, stehen vor besonderen Herausforderungen in Bezug auf Skalierbarkeit, Kostenmanagement und betriebliche Effizienz. Erfolgreiche Implementierungen erfordern eine sorgfältige Planung in mehreren Dimensionen.
Verteilte Trainingsarchitekturen
Moderne KI-Modelle enthalten oft Milliarden von Parametern, wodurch ein Training auf einer einzelnen GPU unpraktikabel wird. Die Technologien von NVIDIA ermöglichen verschiedene verteilte Trainingsansätze:
Bei der Datenparallelität werden die Trainingsdaten auf mehrere GPUs verteilt, wobei jedes Gerät eine vollständige Kopie des Modells verwaltet. Dieser Ansatz lässt sich gut auf große Batch-Größen skalieren und erweist sich insbesondere bei Aufgaben im Bereich Computer Vision als besonders effektiv.
Bei der Modellparallelität werden verschiedene Modellschichten auf die GPUs verteilt, wodurch das Training von Modellen ermöglicht wird, die für den Speicher eines einzelnen Geräts zu groß sind. Transformer-basierte Sprachmodelle erfordern häufig diesen Ansatz.
Die Pipeline-Parallelität kombiniert Elemente beider Strategien und unterteilt Modelle in Phasen, die verschiedene Datenbatches gleichzeitig verarbeiten. Diese Technik maximiert die GPU-Auslastung und minimiert gleichzeitig den Kommunikationsaufwand.
Unternehmen, die KI-Spezialisierungskurse absolvieren, sollten diese Parallelisierungsstrategien verstehen, da sie die Trainingseffizienz und die Wirtschaftlichkeit grundlegend beeinflussen.
Umweltaspekte und Nachhaltigkeit
Der Rechenaufwand beim KI-Training mit NVIDIA wirft wichtige Fragen zur Nachhaltigkeit auf. Aktuelle Forschungsergebnisse zum nachhaltigen KI-Training durch Hardware-Software-Co-Design zeigen, wie Optimierungsstrategien den Energieverbrauch erheblich senken können, ohne die Modellqualität zu beeinträchtigen.
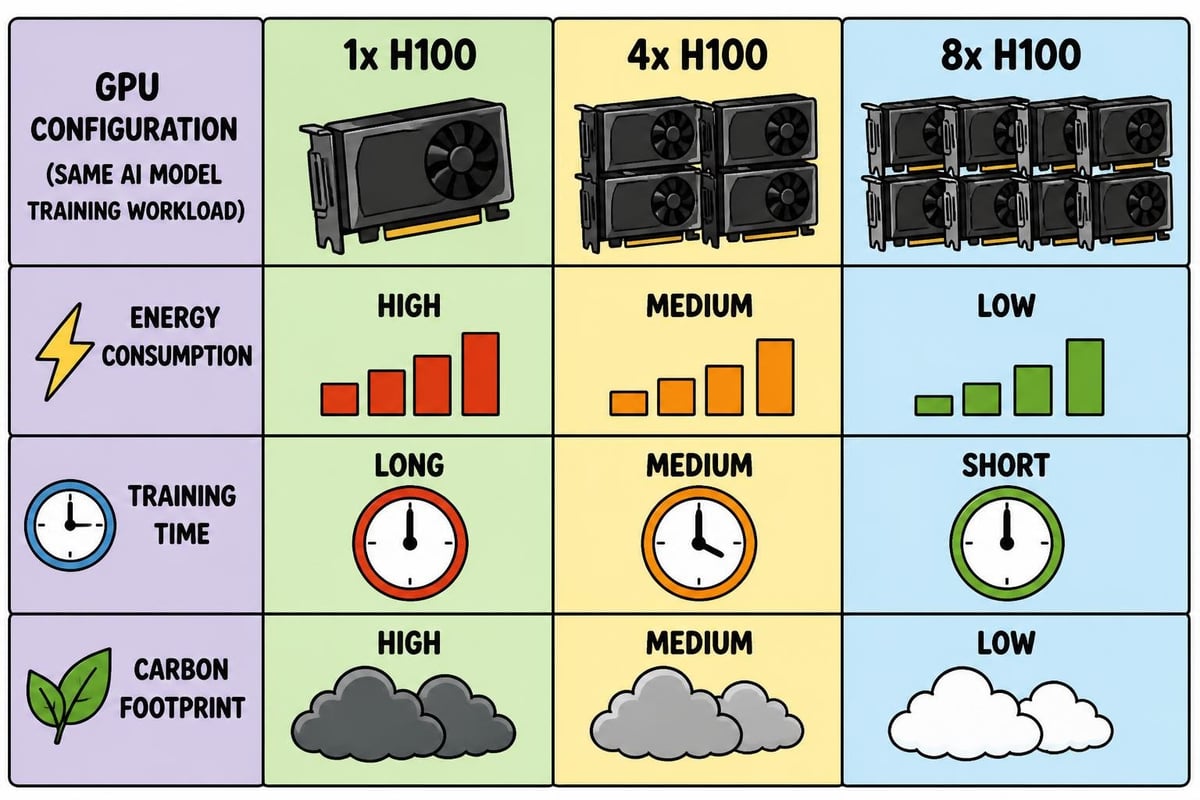
Zu den wichtigsten Nachhaltigkeitsmaßnahmen gehören:
- Einsatz von Training mit gemischter Genauigkeit zur Reduzierung des Rechenaufwands
- Implementierung von Gradienten-Checkpointing zur Steigerung der Speichereffizienz
- Planung von Trainingsaufträgen außerhalb der Spitzenlastzeiten
- Nutzung von Transferlernen, um das Training von Grund auf zu minimieren
- Überwachung der CO₂-Bilanz mithilfe spezieller Tools
Eine umfassende Lebenszyklusanalyse des KI-Trainings auf NVIDIA A100-GPUs zeigt, dass die Umweltauswirkungen über den direkten Energieverbrauch hinausgehen und auch die Herstellung, die Kühlinfrastruktur sowie Aspekte der Entsorgung umfassen.
Praktische Anwendungen und Anwendungsfälle in der Industrie
Die Vielseitigkeit des KI-Trainings mit NVIDIA ermöglicht bahnbrechende Anwendungen in verschiedenen Branchen. Das Verständnis realer Implementierungen hilft Unternehmen dabei, Chancen innerhalb ihrer eigenen Betriebsabläufe zu erkennen.
Autonome Systeme und Robotik
Physikalische KI stellt eine der anspruchsvollsten Anwendungen des maschinellen Lernens dar. Um Roboter für die Ausführung komplexer Aufgaben zu trainieren, müssen riesige Mengen an Sensordaten über ausgefeilte neuronale Netze verarbeitet werden. Der Ansatz von NVIDIA umfasst spezialisierte Tools, die in den Lernressourcen zur physikalischen KI dokumentiert sind.
Jüngste Entwicklungen zeigen bemerkenswerte Fortschritte. NVIDIA hat KI-Roboter entwickelt, die in der Lage sind, GPUs autonom zu installieren, und demonstriert damit, wie Verstärkungslernen in Kombination mit Simulationsumgebungen es Robotern ermöglicht, hochpräzise Aufgaben zu meistern.
Telekommunikation und Netzwerkoptimierung
Das NVIDIA Sionna Research Kit veranschaulicht, wie GPU-beschleunigte Plattformen die Entwicklung und das Testen von KI-Algorithmen für 5G-Netze ermöglichen. Diese spezialisierte Anwendung erfordert das Trainieren von Modellen anhand riesiger Datensätze, die komplexe Signalausbreitungsszenarien abbilden.
Telekommunikationsanwendungen profitieren vom NVIDIA-KI-Training durch:
- Vorausschauende Netzwerkwartung mithilfe von Modellen zur Anomalieerkennung
- Dynamische Ressourcenzuweisung durch bestärkendes Lernen
- Optimierung der Signalverarbeitung mit Faltungsnetzwerken
- Vorhersage des Kundenverhaltens für die Kapazitätsplanung
- Betrugserkennung mithilfe von graphischen neuronalen Netzen
Maximierung des ROI aus Investitionen in NVIDIA-KI-Training
Unternehmen, die in KI-Infrastruktur investieren, müssen sicherstellen, dass sie den maximalen Nutzen aus ihren NVIDIA-KI-Trainingskapazitäten ziehen. Dies erfordert ein Gleichgewicht zwischen technischer Optimierung und strategischer Ausrichtung auf das Geschäft.
Optimierung der Trainingseffizienz
Fachteams können die Trainingseffizienz durch systematische Optimierung erheblich steigern:
Die Hyperparameter-Optimierung stellt die am leichtesten zugängliche Optimierungsmöglichkeit dar. Eine automatisierte Hyperparameter-Suche mit Tools wie Optuna oder Ray Tune kann Konfigurationen identifizieren, die die Trainingszeit um 40–60 % verkürzen und gleichzeitig die Modellgenauigkeit verbessern.
Die Optimierung der Datenpipeline bietet oft verborgene Leistungssteigerungen. Engpässe beim Laden, bei der Vorverarbeitung oder bei der Datenerweiterung können dazu führen, dass GPUs trotz erheblicher Hardware-Investitionen ungenutzt bleiben. Profiling-Tools helfen dabei, diese Ineffizienzen zu identifizieren und zu beseitigen.
Die Auswahl der Modellarchitektur wirkt sich sowohl auf die Trainingsgeschwindigkeit als auch auf die endgültige Leistung aus. Moderne Architekturen wie Vision Transformers oder EfficientNets erzielen mit weniger Parametern überlegene Ergebnisse und reduzieren so den Rechenaufwand erheblich.
Aufbau interner KI-Kompetenzen
Erfolgreiche KI-Initiativen erfordern qualifiziertes Personal, das sowohl die Technologie als auch die geschäftlichen Anwendungsbereiche versteht. Unternehmen verfolgen in der Regel mehrere Strategien zur Talentförderung:
| Ansatz | Zeitrahmen | Investitionsumfang | Geeignet für |
|---|---|---|---|
| Interne Schulungsprogramme | 3–6 Monate | Mittel | Vorhandenes technisches Personal |
| Partnerschaften mit Hochschulen | 1–2 Jahre | Hoch | Langfristige Pipeline |
| Online-Zertifizierungskurse | 1–3 Monate | Niedrig | Schnelle Weiterqualifizierung |
| Bootcamp-Programme | 2–4 Monate | Mittel | Berufliche Neuorientierung |
Fachkräfte, die ihre Fähigkeiten erweitern möchten, können sich die KI-Kurse auf Coursera ansehen oder eine Azure-KI-Zertifizierung anstreben, um ihre Fachkenntnisse im Bereich der cloudbasierten GPU-Infrastruktur unter Beweis zu stellen.
Fortgeschrittene Techniken und zukünftige Entwicklungen
Die Landschaft der NVIDIA-KI-Schulungen entwickelt sich weiterhin rasant weiter. Indem Unternehmen sich über neue Techniken auf dem Laufenden halten, sichern sie sich Wettbewerbsvorteile.
Transferlernen und Grundmodelle
Anstatt Modelle von Grund auf neu zu trainieren, nutzen Unternehmen zunehmend vortrainierte Basismodelle als Ausgangspunkt. Dieser Ansatz verkürzt die Trainingszeit von Wochen auf Stunden und liefert dabei oft überlegene Ergebnisse. Der NGC-Katalog von NVIDIA bietet Zugriff auf Hunderte optimierter, vortrainierter Modelle aus verschiedenen Bereichen.
Strategien zur Feinabstimmung ermöglichen die Anpassung an spezifische Anwendungsfälle:
- Beider Merkmalsextraktion werden vortrainierte Schichten als feste Merkmalsextraktoren verwendet
- Durch das Feinabstimmen der obersten Schichten werden die letzten Klassifizierungsschichten an neue Aufgaben angepasst
- Durchdas Feinabstimmen des gesamten Modells werden alle Gewichte aktualisiert, um eine maximale Anpassung zu erreichen
- Das „Few-Shot“-Lernen erzielt gute Leistungen mit minimalen Trainingsdaten
Integration von automatisiertem maschinellem Lernen
AutoML-Plattformen machen den Zugang zum NVIDIA-KI-Training für alle zugänglich, indem sie komplexe Entscheidungen hinsichtlich der Architekturauswahl, der Hyperparameter-Optimierung und der Trainingsverfahren automatisieren. Diese Tools ermöglichen es Fachexperten ohne tiefgreifende Kenntnisse im Bereich des maschinellen Lernens, effektive Modelle zu entwickeln.
Die internen Praktiken von NVIDIA verdeutlichen diesen Trend. Das Unternehmen hat seine Code-Produktivität durch die Integration KI-gestützter Entwicklungstools verdreifacht und zeigt damit, wie Automatisierung selbst hochtechnische Arbeitsabläufe beschleunigt.
Verwaltung und Betrieb der Trainingsinfrastruktur
Ein effektives NVIDIA-KI-Training erfordert solide Betriebsabläufe in den Bereichen Infrastrukturmanagement, Überwachung und Wartung.
Überlegungen zu Cloud- und On-Premises-Lösungen
Unternehmen stehen vor wichtigen Entscheidungen darüber, wo sie KI-Trainings-Workloads ausführen sollen:
Das Training in der Cloud bietet mehrere Vorteile, darunter elastische Skalierbarkeit, minimale Investitionskosten und Zugang zu den neuesten Hardware-Generationen. Große Cloud-Anbieter bieten NVIDIA-GPU-Instanzen mit verschiedenen Konfigurationen an, die für unterschiedliche Workloads optimiert sind.
Eine lokale Infrastruktur bietet vorhersehbare Kosten für dauerhafte Workloads, erhöhte Datensicherheit und vollständige Kontrolle über die Hardwarekonfigurationen. Unternehmen mit konstantem Trainingsbedarf empfinden eine lokale Bereitstellung über einen Zeitraum von mehreren Jahren hinweg oft als wirtschaftlicher.
Hybride Ansätze kombinieren beide Modelle, indem sie die Infrastruktur vor Ort als Grundkapazität nutzen und bei Spitzenauslastung oder experimentellen Workloads auf Cloud-Ressourcen zurückgreifen.
Überwachung und Leistungsanalyse
Eine umfassende Überwachung stellt sicher, dass die NVIDIA-KI-Trainingsinfrastruktur die erwartete Leistung erbringt, und identifiziert Optimierungsmöglichkeiten:
- Kennzahlen zur GPU-Auslastung, die unausgelastete Kapazitäten aufzeigen
- Messungen des Trainingsdurchsatzes zur Erfassung der Samples pro Sekunde
- Speichernutzungsmuster, die Engpässe identifizieren
- Stromverbrauchsdaten zur Überwachung der Nachhaltigkeit
- Kostenanalysen zur Budgetoptimierung
Fachleute, die an Kursen zum Thema KI-Management teilnehmen, profitieren vom Verständnis dieser betrieblichen Aspekte, da das Infrastrukturmanagement zunehmend über den Erfolg von KI-Initiativen entscheidet.
Personalentwicklung und Kompetenzaufbau
Der rasante Fortschritt der KI-Schulungstechnologien von NVIDIA stellt die Personalentwicklung vor ständige Herausforderungen. Unternehmen müssen die Kompetenzen ihrer Teams kontinuierlich aktualisieren, um neue Funktionen und bewährte Verfahren nutzen zu können.
Strukturierte Lernpfade
Effektive KI-Schulungsprogramme folgen progressiven Lernpfaden, die zunächst grundlegendes Wissen vermitteln, bevor auf spezialisierte Themen eingegangen wird:
- Grundlegende Konzepte aus den Bereichen Theorie des maschinellen Lernens und Mathematik
- Beherrschung der Frameworks mit praktischer Erfahrung in PyTorch oder TensorFlow
- GPU-Programmierung mit Verständnis der CUDA-Grundlagen und Optimierungsprinzipien
- Verteilte Systeme zur Erforschung des Trainings mit mehreren GPUs und Knoten
- Produktive Bereitstellung mit Schwerpunkt auf Modellbereitstellung und -überwachung
Unternehmen können sich in Kursen zum Thema „KI im Geschäftsleben“ mit diesem Thema auseinandersetzen, die technische Kompetenzen mit strategischen Geschäftsanwendungen verbinden und so sicherstellen, dass die Teams sowohl die Umsetzung als auch die Wertschöpfung verstehen.
Zertifizierung und Qualifikationsnachweise
Berufliche Zertifizierungen bestätigen Fachkompetenz und bieten strukturierte Lernziele. Zu den relevanten Zertifizierungen für Praktiker im Bereich NVIDIA-KI-Schulungen zählen die Zertifizierungen des NVIDIA Deep Learning Institute, KI-Zertifizierungen von Cloud-Anbietern sowie frameworkspezifische Qualifikationen.
Das Zertifizierungsangebot umfasst Optionen für verschiedene Erfahrungsstufen:
- Zertifizierungen für Einsteiger, die grundlegende Kenntnisse vermitteln
- Associate-Zertifizierungen, die praktische Implementierungsfähigkeiten nachweisen
- Professional-Zertifizierungen, die fortgeschrittenes architektonisches Fachwissen bestätigen
- Spezialzertifizierungen mit Schwerpunkt auf bestimmten Bereichen wie Computer Vision oder NLP
Die Beherrschung der KI-Trainingsfunktionen von NVIDIA ist für Unternehmen und Fachleute, die sich in der KI-getriebenen Wirtschaft bewegen, von strategischer Bedeutung. Die Kombination aus leistungsstarken GPU-Architekturen, optimierten Software-Frameworks und neuen Best Practices schafft beispiellose Innovationsmöglichkeiten branchenübergreifend.
Ganz gleich, ob Sie interne KI-Kompetenzen aufbauen, sich beruflich weiterbilden oder eine organisatorische Transformation leiten – strukturiertes Lernen beschleunigt Ihren Weg zum Ziel. MammothClub bietet umfassende KI-Schulungsressourcen, darunter On-Demand-Kurse, interaktive Bootcamps und Zertifizierungsprogramme für Unternehmen, die Ihnen dabei helfen sollen, NVIDIA-Technologien zu beherrschen und KI-Lösungen effektiv einzusetzen. Unsere KI-gestützte Lernplattform macht komplexe Themen zugänglich und liefert gleichzeitig messbare Ergebnisse, die echte geschäftliche Auswirkungen erzielen.