The artificial intelligence revolution depends on one critical factor: computational power. As organizations race to implement AI solutions across their operations, NVIDIA has emerged as the undisputed leader in providing the hardware and software infrastructure that makes advanced machine learning possible. Understanding nvidia ai training fundamentals has become essential for any professional or organization seeking to leverage artificial intelligence effectively. From small startups to Fortune 500 companies, the ability to train sophisticated AI models quickly and efficiently determines competitive advantage in today's digital economy.
Understanding NVIDIA's Role in AI Training Infrastructure
NVIDIA's dominance in artificial intelligence extends far beyond manufacturing graphics processing units. The company has created an entire ecosystem designed specifically for machine learning workloads, combining cutting-edge hardware with optimized software frameworks that dramatically accelerate the training process.
GPU Architecture for Machine Learning Workloads
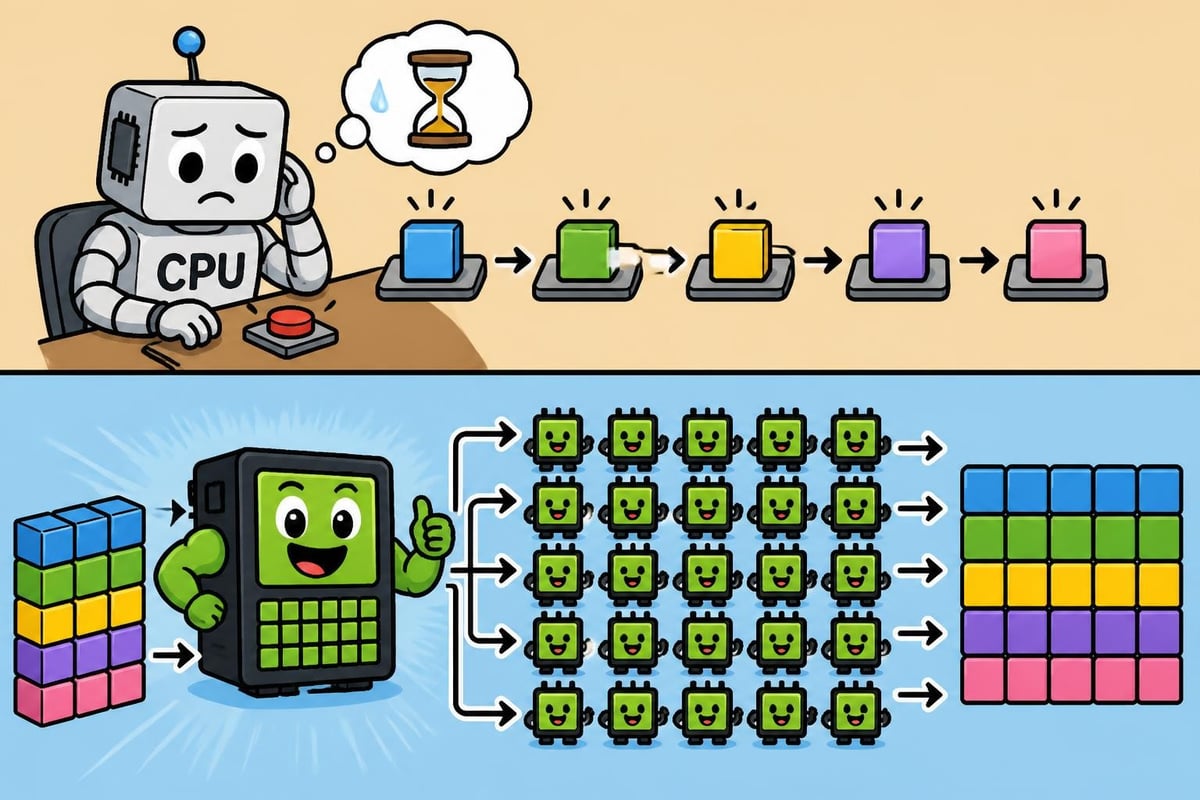
The foundation of nvidia ai training lies in NVIDIA's specialized GPU architectures. Unlike traditional central processing units that handle tasks sequentially, GPUs perform thousands of parallel calculations simultaneously. This parallel processing capability proves essential for training neural networks, which require millions of matrix multiplications and tensor operations.
NVIDIA's latest Blackwell architecture represents a quantum leap in AI training performance. According to NVIDIA's MLPerf Training v5.0 benchmark results, the new architecture delivers unprecedented speed improvements across various AI workloads. The architecture introduces several key innovations:
- Enhanced tensor cores optimized for mixed-precision calculations
- Increased memory bandwidth to eliminate data transfer bottlenecks
- Advanced multi-instance GPU technology for workload isolation
- Improved power efficiency for sustainable large-scale deployments
For professionals exploring AI hardware options, understanding these architectural advances helps inform infrastructure decisions. Many organizations start their AI journey by selecting the right GPU for AI training based on their specific workload requirements and budget constraints.
Software Frameworks and Tools for NVIDIA AI Training
Hardware alone cannot deliver optimal AI training performance. NVIDIA has invested heavily in developing comprehensive software stacks that maximize GPU utilization and simplify the development process for data scientists and machine learning engineers.
CUDA and cuDNN Foundations
CUDA (Compute Unified Device Architecture) serves as the fundamental programming model for NVIDIA GPUs. This parallel computing platform allows developers to harness GPU power for general-purpose processing tasks. The cuDNN library builds upon CUDA, providing highly optimized primitives specifically for deep neural networks.
These foundational technologies enable:
- Accelerated linear algebra operations through optimized BLAS libraries
- Efficient convolution algorithms for computer vision applications
- Optimized recurrent network implementations for natural language processing
- Fast normalization and activation functions across all network layers
- Memory-efficient training techniques for larger model architectures
Framework Integration and Optimization
Popular machine learning frameworks leverage NVIDIA's software stack to deliver exceptional performance. TensorFlow, PyTorch, and JAX all include native CUDA support, allowing developers to write framework-agnostic code that automatically benefits from GPU acceleration.
| Framework | NVIDIA Integration | Primary Use Cases | Performance Benefits |
|---|---|---|---|
| PyTorch | Native CUDA support | Research, prototyping | Dynamic computation graphs |
| TensorFlow | XLA compilation | Production deployment | Graph optimization |
| JAX | GPU-native operations | Scientific computing | Automatic differentiation |
| MXNet | Gluon API | Scalable training | Hybrid programming |
The NVIDIA NeMo framework exemplifies this integration approach, providing an open-source pipeline specifically designed for training video foundation models with optimal GPU utilization.
Enterprise AI Training Strategies with NVIDIA Technology
Organizations implementing nvidia ai training face unique challenges around scalability, cost management, and operational efficiency. Successful deployments require careful planning across multiple dimensions.
Distributed Training Architectures
Modern AI models often contain billions of parameters, making single-GPU training impractical. NVIDIA's technologies enable several distributed training approaches:
Data Parallelism splits training data across multiple GPUs, with each device maintaining a complete model copy. This approach scales well for large batch sizes and proves particularly effective for computer vision tasks.
Model Parallelism distributes different model layers across GPUs, enabling training of models too large for single-device memory. Transformer-based language models frequently require this approach.
Pipeline Parallelism combines elements of both strategies, segmenting models into stages that process different data batches simultaneously. This technique maximizes GPU utilization while minimizing communication overhead.
Organizations pursuing AI specialization courses should understand these parallelization strategies, as they fundamentally impact training efficiency and cost-effectiveness.
Environmental Considerations and Sustainability
The computational demands of nvidia ai training raise important sustainability questions. Recent research into sustainable AI training through hardware-software co-design demonstrates how optimization strategies can significantly reduce energy consumption without sacrificing model quality.
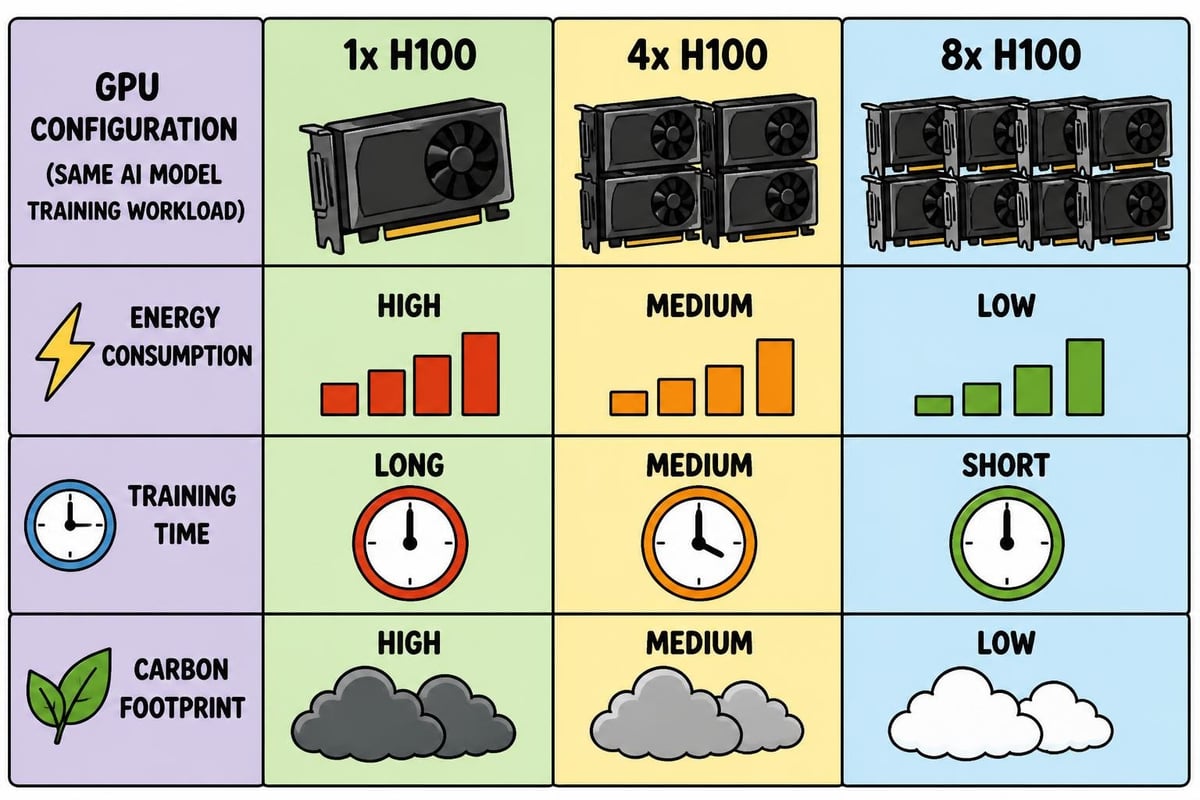
Key sustainability practices include:
- Utilizing mixed-precision training to reduce computational requirements
- Implementing gradient checkpointing for memory efficiency
- Scheduling training jobs during off-peak energy hours
- Leveraging transfer learning to minimize training from scratch
- Monitoring carbon impact through specialized tools
A comprehensive life cycle assessment of AI training on NVIDIA A100 GPUs reveals that environmental impacts extend beyond direct energy consumption, encompassing manufacturing, cooling infrastructure, and end-of-life considerations.
Practical Applications and Industry Use Cases
The versatility of nvidia ai training enables transformative applications across diverse industries. Understanding real-world implementations helps organizations identify opportunities within their own operations.
Autonomous Systems and Robotics
Physical AI represents one of the most demanding applications of machine learning. Training robots to perform complex tasks requires processing vast amounts of sensor data through sophisticated neural networks. NVIDIA's approach includes specialized tools documented in their physical AI learning resources.
Recent developments showcase remarkable progress. NVIDIA has developed AI robots capable of autonomously installing GPUs, demonstrating how reinforcement learning combined with simulation environments enables robots to master high-precision tasks.
Telecommunications and Network Optimization
The NVIDIA Sionna Research Kit illustrates how GPU-accelerated platforms enable development and testing of AI algorithms for 5G networks. This specialized application requires training models on massive datasets representing complex signal propagation scenarios.
Telecommunications applications benefit from nvidia ai training through:
- Predictive network maintenance using anomaly detection models
- Dynamic resource allocation through reinforcement learning
- Signal processing optimization with convolutional networks
- Customer behavior prediction for capacity planning
- Fraud detection using graph neural networks
Maximizing ROI from NVIDIA AI Training Investments
Organizations investing in AI infrastructure must ensure they extract maximum value from their nvidia ai training capabilities. This requires balancing technical optimization with strategic business alignment.
Training Efficiency Optimization
Professional teams can dramatically improve training efficiency through systematic optimization:
Hyperparameter Tuning represents the most accessible optimization opportunity. Automated hyperparameter search using tools like Optuna or Ray Tune can identify configurations that reduce training time by 40-60% while improving model accuracy.
Data Pipeline Optimization often provides hidden performance gains. Bottlenecks in data loading, preprocessing, or augmentation can cause GPUs to sit idle despite significant hardware investments. Profiling tools help identify and eliminate these inefficiencies.
Model Architecture Selection impacts both training speed and final performance. Modern architectures like Vision Transformers or EfficientNets achieve superior results with fewer parameters, reducing computational requirements substantially.
Building Internal AI Capabilities
Successful AI initiatives require skilled personnel who understand both the technology and business applications. Organizations typically pursue multiple talent development strategies:
| Approach | Timeframe | Investment Level | Suitable For |
|---|---|---|---|
| Internal training programs | 3-6 months | Medium | Existing technical staff |
| University partnerships | 1-2 years | High | Long-term pipeline |
| Online certification courses | 1-3 months | Low | Rapid upskilling |
| Bootcamp programs | 2-4 months | Medium | Career transitions |
Professionals seeking to enhance their capabilities might explore AI courses on Coursera or pursue Azure AI certification to demonstrate expertise with cloud-based GPU infrastructure.
Advanced Techniques and Future Directions
The nvidia ai training landscape continues evolving rapidly. Staying current with emerging techniques ensures organizations maintain competitive advantages.
Transfer Learning and Foundation Models
Rather than training models from scratch, organizations increasingly leverage pre-trained foundation models as starting points. This approach reduces training time from weeks to hours while often delivering superior results. NVIDIA's NGC catalog provides access to hundreds of optimized pre-trained models across various domains.
Fine-tuning strategies enable customization for specific use cases:
- Feature extraction uses pre-trained layers as fixed feature extractors
- Fine-tuning top layers adapts final classification layers to new tasks
- Full model fine-tuning updates all weights for maximum customization
- Few-shot learning achieves good performance with minimal training data
Automated Machine Learning Integration
AutoML platforms democratize access to nvidia ai training by automating complex decisions around architecture selection, hyperparameter tuning, and training procedures. These tools enable domain experts without deep machine learning expertise to develop effective models.
NVIDIA's internal practices demonstrate this trend. The company has tripled its code output by integrating AI-powered development tools, showing how automation accelerates even highly technical workflows.
Training Infrastructure Management and Operations
Effective nvidia ai training requires robust operational practices around infrastructure management, monitoring, and maintenance.
Cloud Versus On-Premises Considerations
Organizations face critical decisions about where to run AI training workloads:
Cloud-based training offers several advantages including elastic scalability, minimal capital expenditure, and access to latest hardware generations. Major cloud providers offer NVIDIA GPU instances with various configurations optimized for different workloads.
On-premises infrastructure provides predictable costs for sustained workloads, enhanced data security, and complete control over hardware configurations. Organizations with consistent training demands often find on-premises deployment more economical over multi-year periods.
Hybrid approaches combine both models, using on-premises infrastructure for baseline capacity while bursting to cloud resources for peak demands or experimental workloads.
Monitoring and Performance Analytics
Comprehensive monitoring ensures nvidia ai training infrastructure delivers expected performance and identifies optimization opportunities:
- GPU utilization metrics revealing underused capacity
- Training throughput measurements tracking samples per second
- Memory usage patterns identifying bottlenecks
- Power consumption data for sustainability tracking
- Cost analytics for budget optimization
Professionals pursuing AI management courses benefit from understanding these operational considerations, as infrastructure management increasingly determines AI initiative success.
Workforce Development and Skill Building
The rapid advancement of nvidia ai training technologies creates ongoing challenges around workforce development. Organizations must continuously update their team's capabilities to leverage new features and best practices.
Structured Learning Pathways
Effective AI training programs follow progressive learning pathways that build foundational knowledge before advancing to specialized topics:
- Foundational concepts covering machine learning theory and mathematics
- Framework proficiency with hands-on PyTorch or TensorFlow experience
- GPU programming understanding CUDA basics and optimization principles
- Distributed systems exploring multi-GPU and multi-node training
- Production deployment focusing on model serving and monitoring
Organizations might explore AI in business courses that connect technical capabilities with strategic business applications, ensuring teams understand both implementation and value creation.
Certification and Credentialing
Professional certifications validate expertise and provide structured learning objectives. Relevant certifications for nvidia ai training practitioners include NVIDIA's Deep Learning Institute certifications, cloud provider AI certifications, and framework-specific credentials.
The certification landscape includes options for various experience levels:
- Entry-level certifications establishing foundational knowledge
- Associate certifications demonstrating practical implementation skills
- Professional certifications validating advanced architectural expertise
- Specialty certifications focusing on specific domains like computer vision or NLP
Mastering nvidia ai training capabilities represents a strategic imperative for organizations and professionals navigating the AI-driven economy. The combination of powerful GPU architectures, optimized software frameworks, and emerging best practices creates unprecedented opportunities for innovation across industries.
Whether you're building internal AI capabilities, pursuing professional development, or leading organizational transformation, structured learning accelerates your journey. MammothClub provides comprehensive AI training resources including on-demand courses, interactive bootcamps, and corporate certification programs designed to help you master NVIDIA technologies and deploy AI solutions effectively. Our AI-powered learning platform makes complex topics accessible while delivering measurable results that drive real business impact.