人工知能(AI)革命は、ある重要な要素、すなわち「計算能力」にかかっています。各組織が業務全般にAIソリューションを導入しようと競い合う中、NVIDIAは、高度な機械学習を可能にするハードウェアおよびソフトウェアインフラの提供において、誰もが認めるリーダーとしての地位を確立しました。人工知能を効果的に活用しようとする専門家や組織にとって、NVIDIAのAIトレーニングの基礎を理解することは不可欠となっています。 小規模なスタートアップからフォーチュン500企業に至るまで、高度なAIモデルを迅速かつ効率的にトレーニングする能力こそが、今日のデジタル経済における競争優位性を決定づける要素となっています。
AIトレーニングインフラにおけるNVIDIAの役割を理解する
NVIDIAの人工知能分野における優位性は、グラフィックスプロセッシングユニット(GPU)の製造をはるかに超えています。同社は、機械学習のワークロードに特化した包括的なエコシステムを構築しており、最先端のハードウェアと、トレーニングプロセスを劇的に加速させる最適化されたソフトウェアフレームワークを組み合わせています。
機械学習ワークロード向けのGPUアーキテクチャ
NVIDIAのAIトレーニングの基盤は、NVIDIA独自のGPUアーキテクチャにあります。タスクを順次処理する従来の中央処理装置(CPU)とは異なり、GPUは数千もの並列計算を同時に実行します。この並列処理能力は、数百万回もの行列乗算やテンソル演算を必要とするニューラルネットワークのトレーニングにおいて不可欠です。
NVIDIAの最新アーキテクチャ「Blackwell」は、AIトレーニング性能において飛躍的な進歩をもたらします。NVIDIAのMLPerf Training v5.0ベンチマーク結果によると、この新しいアーキテクチャは、さまざまなAIワークロードにおいて、かつてないほどの速度向上を実現しています。このアーキテクチャには、いくつかの重要な革新が導入されています:
- 混合精度演算に最適化された強化型テンソルコア
- データ転送のボトルネックを解消するためのメモリ帯域幅の拡大
- ワークロードの分離を実現する高度なマルチインスタンスGPU技術
- 持続可能な大規模展開を実現する電力効率の向上
AIハードウェアの選択肢を検討している専門家にとって、こうしたアーキテクチャの進歩を理解することは、インフラストラクチャの決定に役立ちます。多くの組織は、特定のワークロード要件や予算の制約に基づいて、AIトレーニングに適したGPUを選択することから、AIの導入を開始しています。
NVIDIA AIトレーニング向けソフトウェアフレームワークとツール
ハードウェアだけでは、最適なAIトレーニング性能を実現することはできません。NVIDIAは、GPUの利用率を最大化し、データサイエンティストや機械学習エンジニアの開発プロセスを簡素化する包括的なソフトウェアスタックの開発に多大な投資を行ってきました。
CUDAおよびcuDNNの基礎
CUDA(Compute Unified Device Architecture)は、NVIDIA GPUの基盤となるプログラミングモデルです。この並列コンピューティングプラットフォームにより、開発者は汎用的な処理タスクにGPUの性能を活用することができます。cuDNNライブラリはCUDAを基盤としており、深層ニューラルネットワークに特化した高度に最適化されたプリミティブを提供します。
これらの基盤技術により、以下のことが可能になります:
- 最適化されたBLASライブラリによる線形代数演算の高速化
- コンピュータビジョンアプリケーション向けの効率的な畳み込みアルゴリズム
- 自然言語処理向けの最適化されたリカレントネットワークの実装
- すべてのネットワーク層にわたる高速な正規化および活性化関数
- 大規模なモデルアーキテクチャ向けのメモリ効率の高い学習手法
フレームワークの統合と最適化
主要な機械学習フレームワークは、NVIDIAのソフトウェアスタックを活用して卓越したパフォーマンスを実現しています。TensorFlow、PyTorch、JAXはいずれもネイティブなCUDAサポートを備えており、開発者はフレームワークに依存しないコードを記述するだけで、自動的にGPUによる高速化の恩恵を受けることができます。
| フレームワーク | NVIDIAとの統合 | 主なユースケース | パフォーマンス上のメリット |
|---|---|---|---|
| PyTorch | ネイティブ CUDA サポート | 研究、プロトタイピング | 動的な計算グラフ |
| TensorFlow | XLAコンパイル | 本番環境へのデプロイ | グラフの最適化 |
| JAX | GPUネイティブ演算 | 科学計算 | 自動微分 |
| MXNet | Gluon API | スケーラブルなトレーニング | ハイブリッドプログラミング |
NVIDIA NeMoフレームワークは、この統合アプローチの好例であり、GPUを最適に活用して動画基盤モデルを学習させるために特別に設計されたオープンソースのパイプラインを提供しています。
NVIDIAテクノロジーを活用したエンタープライズAIトレーニング戦略
NVIDIAのAIトレーニングを導入する組織は、スケーラビリティ、コスト管理、運用効率といった面で特有の課題に直面しています。導入を成功させるには、多角的な観点からの綿密な計画が不可欠です。
分散型トレーニングアーキテクチャ
最新のAIモデルは、多くの場合数十億ものパラメータを含むため、単一のGPUによるトレーニングは現実的ではありません。NVIDIAのテクノロジーにより、以下のようないくつかの分散トレーニング手法が可能になります:
データ並列処理では、トレーニングデータを複数のGPUに分割し、各デバイスがモデルの完全なコピーを保持します。このアプローチは、バッチサイズが大きい場合に優れたスケーラビリティを発揮し、特にコンピュータビジョンタスクにおいて高い効果を発揮します。
モデル並列処理では、モデルの各層を複数のGPUに分散させることで、単一デバイスのメモリ容量では収まらない大規模なモデルの学習を可能にします。トランスフォーマーベースの言語モデルでは、このアプローチが頻繁に必要とされます。
パイプライン並列処理は、これら2つの戦略の要素を組み合わせ、モデルを複数の段階に分割し、異なるデータバッチを同時に処理します。この手法により、GPUの利用率を最大化しつつ、通信オーバーヘッドを最小限に抑えることができます。
AI専門コースを受講する組織は、これらの並列化戦略を理解しておく必要があります。これらは、トレーニングの効率や費用対効果に根本的な影響を与えるからです。
環境への配慮と持続可能性
NVIDIAのAIトレーニングに伴う計算負荷は、持続可能性に関する重要な課題を提起しています。ハードウェアとソフトウェアの共同設計を通じた持続可能なAIトレーニングに関する最近の研究では、モデルの品質を損なうことなく、最適化戦略によってエネルギー消費を大幅に削減できることが実証されています。
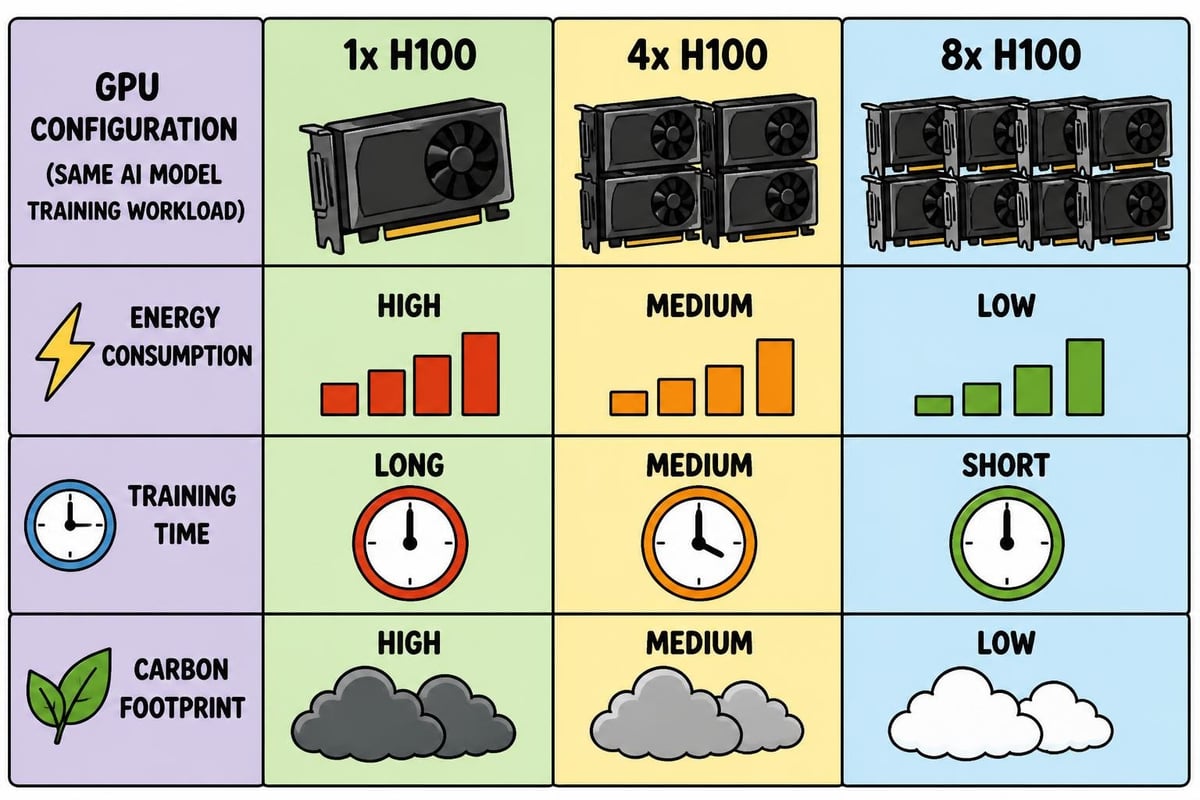
主な持続可能性への取り組みには、以下のものが含まれます:
- 混合精度トレーニングを活用して計算要件を削減する
- メモリ効率向上のための勾配チェックポイント機能の実装
- 電力需要のピーク時を避けてトレーニングジョブをスケジューリングする
- 転移学習を活用し、ゼロからの学習を最小限に抑える
- 専用ツールを用いたカーボンインパクトのモニタリング
NVIDIA A100 GPU における AI トレーニングの包括的なライフサイクルアセスメントによると、環境への影響は直接的なエネルギー消費にとどまらず、製造、冷却インフラ、および廃棄時の考慮事項にまで及ぶことが明らかになりました。
実用的な応用例と業界での活用事例
NVIDIAのAIトレーニングの汎用性により、多様な業界で革新的なアプリケーションが実現しています。実世界の導入事例を理解することで、組織は自社の業務における機会を特定しやすくなります。
自律システムとロボティクス
フィジカルAIは、機械学習の中でも特に高度な処理が求められるアプリケーションの一つです。ロボットに複雑なタスクを実行させるためには、洗練されたニューラルネットワークを通じて膨大な量のセンサーデータを処理する必要があります。NVIDIAのアプローチには、同社のフィジカルAI学習リソースに詳述されている専用ツールが含まれています。
最近の進展は、目覚ましい進歩を示しています。NVIDIAは、GPUを自律的に取り付けられるAIロボットを開発し、強化学習とシミュレーション環境を組み合わせることで、ロボットが高精度なタスクを習得できることを実証しました。
通信およびネットワークの最適化
NVIDIAの「Sionna Research Kit」は、GPU加速プラットフォームが5Gネットワーク向けのAIアルゴリズムの開発とテストをどのように可能にするかを示しています。この特殊なアプリケーションでは、複雑な信号伝搬シナリオを反映した膨大なデータセットを用いてモデルを学習させる必要があります。
通信アプリケーションは、以下の点においてNVIDIAのAIトレーニングの恩恵を受けています:
- 異常検知モデルを用いた予測型ネットワーク保守
- 強化学習による動的なリソース割り当て
- 畳み込みニューラルネットワークによる信号処理の最適化
- 容量計画のための顧客行動予測
- グラフニューラルネットワークを用いた不正検知
NVIDIAのAIトレーニング投資からのROIを最大化
AIインフラに投資する組織は、NVIDIAのAIトレーニング機能から最大限の価値を引き出す必要があります。そのためには、技術的な最適化と戦略的なビジネスとの整合性のバランスをとることが求められます。
トレーニング効率の最適化
専門チームは、体系的な最適化を通じてトレーニング効率を劇的に向上させることができます:
ハイパーパラメータのチューニングは、最も手軽に実施できる最適化の機会です。OptunaやRay Tuneなどのツールを用いた自動ハイパーパラメータ探索により、モデルの精度を向上させつつ、トレーニング時間を40~60%短縮できる設定を特定することができます。
データパイプラインの最適化は、しばしば隠れたパフォーマンス向上の余地をもたらします。データの読み込み、前処理、またはデータ拡張におけるボトルネックは、多額のハードウェア投資を行ってもGPUが遊休状態になってしまう原因となります。プロファイリングツールを活用することで、こうした非効率性を特定し、解消することができます。
モデルアーキテクチャの選択は、学習速度と最終的なパフォーマンスの両方に影響を与えます。Vision TransformersやEfficientNetsといった最新のアーキテクチャは、より少ないパラメータで優れた結果を達成し、計算要件を大幅に削減します。
社内AI能力の構築
AIイニシアチブを成功させるには、技術とビジネスへの応用双方を理解する熟練した人材が必要です。組織では通常、以下のような複数の人材育成戦略を推進しています:
| アプローチ | 期間 | 投資規模 | 適している対象 |
|---|---|---|---|
| 社内研修プログラム | 3~6ヶ月 | 中 | 既存の技術スタッフ |
| 大学との提携 | 1~2年 | 高 | 長期的な人材パイプライン |
| オンライン認定コース | 1~3ヶ月 | 低 | 短期間でのスキルアップ |
| ブートキャンプ・プログラム | 2~4ヶ月 | 中 | キャリアチェンジ |
スキルアップを目指すプロフェッショナルの方は、CourseraのAIコースを受講したり、Azure AI認定資格を取得して、クラウドベースのGPUインフラに関する専門知識を証明したりすることを検討してみてはいかがでしょうか。
高度な技術と今後の方向性
NVIDIAのAIトレーニング環境は、急速に進化し続けています。新たな技術動向を常に把握しておくことで、組織は競争優位性を維持することができます。
転移学習とファウンデーションモデル
モデルをゼロから学習させるのではなく、事前学習済みの基盤モデルを出発点として活用する組織が増えています。このアプローチにより、学習時間を数週間から数時間に短縮できるだけでなく、多くの場合、優れた結果が得られます。NVIDIAのNGCカタログでは、さまざまな分野にわたる数百もの最適化された事前学習済みモデルを利用できます。
ファインチューニング戦略により、特定のユースケースに合わせたカスタマイズが可能になります:
- 特徴量抽出では、事前学習済みのレイヤーを固定の特徴量抽出器として使用します
- 最上位層の微調整により、最終的な分類層を新しいタスクに適応させます
- モデル全体の微調整により、すべての重みを更新し、最大限のカスタマイズを実現します
- ファウショット学習は、最小限の学習データで良好な性能を実現します
自動機械学習の統合
AutoMLプラットフォームは、アーキテクチャの選択、ハイパーパラメータの調整、トレーニング手順といった複雑な決定を自動化することで、NVIDIAのAIトレーニングへのアクセスを広く普及させます。これらのツールにより、機械学習の専門知識が深くなくても、各分野の専門家が効果的なモデルを開発できるようになります。
NVIDIAの社内実践もこの傾向を裏付けています。同社はAIを活用した開発ツールを統合することでコードの生産量を3倍に増やしており、自動化がいかに高度な技術的ワークフローさえも加速させるかを示しています。
トレーニングインフラの管理と運用
効果的なNVIDIA AIトレーニングには、インフラストラクチャの管理、監視、保守に関する堅牢な運用慣行が不可欠です。
クラウドとオンプレミスの比較検討事項
組織は、AIトレーニングのワークロードをどこで実行するかという重要な決定に直面しています:
クラウドベースのトレーニングには、弾力的なスケーラビリティ、設備投資の最小化、最新世代のハードウェアへのアクセスなど、いくつかの利点があります。主要なクラウドプロバイダーは、さまざまなワークロードに最適化された多様な構成のNVIDIA GPUインスタンスを提供しています。
オンプレミスインフラストラクチャは、継続的なワークロードに対して予測可能なコスト、強化されたデータセキュリティ、およびハードウェア構成に対する完全な制御を提供します。トレーニング需要が一定している組織では、数年単位で見るとオンプレミス展開の方が経済的であることが多いです。
ハイブリッドアプローチは、両方のモデルを組み合わせたもので、ベースラインの容量にはオンプレミスインフラストラクチャを使用し、需要のピーク時や実験的なワークロードにはクラウドリソースをバースト的に活用します。
監視とパフォーマンス分析
包括的な監視により、NVIDIAのAIトレーニングインフラストラクチャが期待通りのパフォーマンスを発揮することを保証し、最適化の機会を特定します:
- GPU使用率の指標により、十分に活用されていない容量を明らかにします
- 1秒あたりのサンプル数を追跡するトレーニングスループット測定
- ボトルネックを特定するメモリ使用パターン
- 持続可能性の追跡のための消費電力データ
- 予算最適化のためのコスト分析
インフラ管理がAIイニシアチブの成否をますます左右するようになる中、AI管理コースを受講する専門家は、こうした運用上の考慮事項を理解することで大きなメリットを得ることができます。
人材育成とスキル向上
NVIDIAのAIトレーニング技術の急速な進歩は、人材育成に関して継続的な課題を生み出しています。組織は、新しい機能やベストプラクティスを活用するために、チームの能力を絶えず向上させなければなりません。
体系化された学習パス
効果的なAIトレーニングプログラムは、基礎知識を固めてから専門的なトピックに進むという段階的な学習パスをたどります:
- 機械学習の理論と数学を網羅した基礎概念
- PyTorchやTensorFlowを用いた実践的な経験を通じたフレームワークの習熟
- GPUプログラミング:CUDAの基礎と最適化の原則の理解
- マルチGPUおよびマルチノードトレーニングを扱う分散システム
- モデルサービングとモニタリングに重点を置いた本番環境へのデプロイ
企業は、技術的な能力と戦略的なビジネス活用を結びつけるビジネス向けAIコースを検討することで、チームが実装と価値創出の両方を理解できるようにすることができます。
認定および資格取得
専門資格は専門知識を証明し、体系的な学習目標を提供します。NVIDIAのAIトレーニング実践者に関連する資格には、NVIDIAのDeep Learning Institute認定資格、クラウドプロバイダーのAI認定資格、およびフレームワーク固有の資格などがあります。
認定資格の全体像には、さまざまな経験レベルに対応した選択肢が含まれています:
- 基礎知識を確立するエントリーレベルの認定資格
- 実践的な実装スキルを示すアソシエイト認定
- 高度なアーキテクチャの専門知識を証明するプロフェッショナル認定
- コンピュータビジョンやNLPといった特定の分野に特化したスペシャリティ認定
AI主導の経済を生き抜く組織や専門家にとって、NVIDIAのAIトレーニング機能を習得することは戦略的に不可欠です。強力なGPUアーキテクチャ、最適化されたソフトウェアフレームワーク、そして新たなベストプラクティスの組み合わせにより、あらゆる業界において前例のないイノベーションの機会が生まれています。
社内のAI能力を構築する場合でも、専門能力の向上を目指す場合でも、あるいは組織変革を主導する場合でも、体系的な学習はあなたの道のりを加速させます。MammothClubは、NVIDIAの技術を習得し、AIソリューションを効果的に導入できるよう設計された、オンデマンドコース、インタラクティブなブートキャンプ、企業向け認定プログラムなど、包括的なAIトレーニングリソースを提供しています。 当社のAIを活用した学習プラットフォームは、複雑なトピックを分かりやすく解説すると同時に、ビジネスに真のインパクトをもたらす測定可能な成果をもたらします。