La rápida evolución de la inteligencia artificial ha transformado la forma en que las organizaciones abordan la implementación de la tecnología y el desarrollo de la fuerza laboral. En el centro de esta transformación se encuentra el entrenamiento de aprendizaje automático de la IA, un proceso crítico que permite a los algoritmos aprender de los datos y tomar decisiones inteligentes sin una programación explícita. Comprender los fundamentos del entrenamiento de modelos de aprendizaje automático se ha vuelto esencial para los profesionales que buscan aprovechar todo el potencial de la IA, ya sean científicos de datos, analistas de negocios o líderes tecnológicos que impulsan iniciativas de transformación digital.
Comprender los fundamentos del entrenamiento en aprendizaje automático de la IA
El entrenamiento en aprendizaje automático con IA representa el proceso sistemático de introducir datos en algoritmos para ayudarles a reconocer patrones, hacer predicciones y mejorar el rendimiento con el tiempo. Este concepto fundamental distingue la IA moderna de los enfoques tradicionales de programación basados en reglas.
Los componentes básicos de la arquitectura de entrenamiento
Toda iniciativa exitosa de entrenamiento en aprendizaje automático de IA se basa en varios elementos interconectados que funcionan conjuntamente para producir modelos precisos y fiables. Los datos de entrenamiento sirven de base, proporcionando ejemplos a partir de los cuales los algoritmos extraen patrones y relaciones significativas.
Los componentes esenciales de la formación incluyen:
- Conjuntos de datos de entrenamiento con ejemplos etiquetados para el aprendizaje supervisado
- Selección de algoritmos basada en la complejidad del problema y las características de los datos
- Configuración de hiperparámetros para optimizar el rendimiento del modelo
- Marcos de validación para evitar el sobreajuste y garantizar la generalización
- Infraestructura computacional para gestionar las demandas de procesamiento
La calidad de los datos de entrenamiento influye directamente en el rendimiento del modelo, tal y como han demostrado numerosas investigaciones. Los estudios que examinan los efectos de la calidad de los datos en el rendimiento del aprendizaje automático revelan que las inconsistencias, los sesgos y la incompletitud de los conjuntos de datos de entrenamiento pueden socavar significativamente la precisión y la fiabilidad del modelo.
Enfoques de entrenamiento supervisado frente a no supervisado
Los diferentes paradigmas de aprendizaje requieren metodologías de entrenamiento distintas. El aprendizaje supervisado entrena modelos utilizando datos etiquetados en los que se conocen las respuestas correctas, lo que permite a los algoritmos aprender las correspondencias entre entradas y salidas. Este enfoque predomina en aplicaciones como la clasificación de imágenes, el reconocimiento de voz y el análisis predictivo.
El aprendizaje no supervisado, por el contrario, descubre patrones ocultos en datos sin etiquetar y sin categorías predeterminadas. El entrenamiento de modelos no supervisados implica configurar algoritmos para identificar clústeres, asociaciones y anomalías de forma independiente. El aprendizaje semisupervisado y el aprendizaje por refuerzo representan enfoques híbridos que combinan elementos de ambos paradigmas.
| Paradigma de entrenamiento | Requisitos de datos | Aplicaciones comunes | Nivel de complejidad |
|---|---|---|---|
| Supervisado | Conjuntos de datos etiquetados | Clasificación, regresión | Moderado |
| No supervisado | Datos sin etiquetar | Agrupamiento, reducción de dimensionalidad | Alta |
| Semi-supervisado | Etiquetado parcialmente | Clasificación de texto, reconocimiento de imágenes | Alta |
| Refuerzo | Señales de recompensa | Juegos, robótica | Muy alto |
Creación de canales de formación eficaces
La creación de canales de formación sólidos en aprendizaje automático con IA requiere una planificación cuidadosa y una ejecución sistemática. El canal transforma los datos brutos en modelos implementables mediante flujos de trabajo estructurados que garantizan la coherencia y la reproducibilidad.
Preparación de datos e ingeniería de características
La preparación de datos consume aproximadamente el 80 % del tiempo en los proyectos típicos de aprendizaje automático. Esta fase crucial implica recopilar datos relevantes, limpiar inconsistencias, manejar valores faltantes y transformar características en formatos que los algoritmos puedan procesar de manera eficaz.
La ingeniería de características representa el arte de seleccionar y crear variables que representen mejor los patrones subyacentes. La experiencia en el ámbito es muy valiosa en este caso, ya que comprender el contexto empresarial ayuda a identificar qué características influirán más en las predicciones del modelo. Para los profesionales que deseen desarrollar estas habilidades, explorar rutas de aprendizaje integrales sobre IA y aprendizaje automático proporciona una orientación estructurada a través de estos conceptos técnicos.
Pasos críticos para la preparación de datos:
- Recopilación de datos de múltiples fuentes y formatos
- Limpieza de datos para eliminar duplicados y corregir errores
- Escalado de características para normalizar los rangos de valores
- Selección de características para identificar las variables más predictivas
- División de datos en conjuntos de entrenamiento, validación y prueba
Selección de modelos y diseño de la arquitectura
La elección de los algoritmos adecuados depende de las características del problema, el volumen de datos y los requisitos de rendimiento. Los árboles de decisión destacan por su interpretabilidad, las redes neuronales manejan relaciones no lineales complejas y los métodos de conjunto combinan múltiples modelos para mejorar la precisión.
Las arquitecturas de aprendizaje profundo introducen una complejidad adicional en el entrenamiento del aprendizaje automático de la IA. Las redes neuronales convolucionales procesan los datos visuales de manera eficiente, las redes recurrentes manejan la información secuencial y las arquitecturas transformadoras han revolucionado el procesamiento del lenguaje natural. Cada arquitectura requiere estrategias de entrenamiento y recursos computacionales específicos, especialmente cuando se trabaja con GPU optimizadas para el entrenamiento de IA.
Técnicas avanzadas de entrenamiento y optimización
El entrenamiento moderno de aprendizaje automático con IA incorpora técnicas sofisticadas que aceleran el aprendizaje, mejoran la precisión y reducen los costes computacionales. Estos métodos avanzados separan los modelos adecuados de los excepcionales.
Aprendizaje por transferencia y modelos preentrenados
El aprendizaje por transferencia aprovecha los conocimientos de los modelos entrenados con grandes conjuntos de datos para impulsar el entrenamiento en tareas relacionadas. En lugar de entrenar desde cero, los profesionales ajustan los modelos preentrenados utilizando conjuntos de datos más pequeños y específicos para cada tarea. Este enfoque reduce drásticamente el tiempo de entrenamiento y los requisitos de datos, al tiempo que a menudo mejora el rendimiento final del modelo.
La proliferación de modelos preentrenados ha democratizado el acceso a las capacidades de IA más avanzadas. Las organizaciones ahora pueden implementar soluciones sofisticadas sin los enormes recursos computacionales que se requerían anteriormente. Sin embargo, comprender cuándo y cómo aplicar el aprendizaje por transferencia requiere una base teórica sólida que pueden proporcionar los cursos de IA para principiantes.
Ajuste de hiperparámetros y optimización de modelos
Los hiperparámetros controlan el proceso de aprendizaje en sí mismo, en lugar de aprenderse a partir de los datos. La tasa de aprendizaje, el tamaño del lote, el número de capas y la fuerza de regularización influyen significativamente en los resultados del entrenamiento. El ajuste sistemático de los hiperparámetros suele marcar la diferencia entre unos resultados mediocres y un rendimiento excepcional.
Las estrategias de optimización más comunes incluyen:
- Búsqueda por cuadrícula que examina todas las combinaciones de parámetros
- Búsqueda aleatoria que muestrea el espacio de parámetros de manera eficiente
- Optimización bayesiana mediante modelos probabilísticos
- Plataformas de aprendizaje automático automatizado (AutoML)
- Búsqueda de arquitectura neuronal para aprendizaje profundo
Según el Informe sobre el índice de inteligencia artificial 2024, las organizaciones adoptan cada vez más enfoques automatizados para la optimización de hiperparámetros, lo que reduce el esfuerzo manual que se requería tradicionalmente y permite descubrir configuraciones superiores que los profesionales humanos podrían pasar por alto.
Enfoques de formación distribuida y federada
A medida que los conjuntos de datos y los modelos crecen, el entrenamiento en una sola máquina se vuelve poco práctico. El entrenamiento distribuido paraleliza el cálculo entre múltiples procesadores o máquinas, lo que permite a las organizaciones entrenar modelos que de otro modo serían imposibles.
Ampliación de la formación en toda la infraestructura
Las plataformas en la nube, como Amazon SageMaker, proporcionan entornos gestionados para el entrenamiento distribuido de aprendizaje automático con IA. Estas plataformas abstraen la complejidad de la infraestructura, distribuyendo automáticamente las cargas de trabajo y gestionando la asignación de recursos. El paralelismo de datos divide los datos de entrenamiento entre varios trabajadores, mientras que el paralelismo de modelos divide el propio modelo cuando supera la capacidad de memoria de un solo dispositivo.
Las decisiones sobre la infraestructura tienen un impacto significativo en la eficiencia y el coste de la formación. Las organizaciones deben equilibrar los requisitos de rendimiento con las limitaciones presupuestarias, teniendo en cuenta factores como los tipos de procesadores, las configuraciones de memoria y el ancho de banda de la red. Comprender estas compensaciones ayuda a los líderes tecnológicos a realizar inversiones en infraestructura bien fundamentadas.
Aprendizaje federado para la formación con preservación de la privacidad
El aprendizaje federado permite la formación colaborativa de modelos sin centralizar los datos confidenciales. Los dispositivos entrenan modelos locales con sus datos, compartiendo solo las actualizaciones de los modelos en lugar de la información sin procesar. El servidor central agrega estas actualizaciones para mejorar el modelo global, que se redistribuye para seguir con la formación local.
La investigación sobre los marcos de aprendizaje federado ha acelerado el desarrollo de técnicas de entrenamiento de aprendizaje automático con IA que preservan la privacidad. Este enfoque beneficia especialmente a los sectores de la sanidad, las finanzas y otros en los que las normativas de privacidad de datos restringen el intercambio de información. El Centro de Aprendizaje Automático de Múnich investiga activamente los enfoques federados junto con otras metodologías de entrenamiento de vanguardia.
| Enfoque de entrenamiento | Ubicación de los datos | Nivel de privacidad | Complejidad | Mejores casos de uso |
|---|---|---|---|---|
| Centralizado | Servidor único | Bajo | Bajo | Aplicaciones no sensibles |
| Distribuido | Varios servidores | Bajo | Moderado | Formación a gran escala |
| Federada | Dispositivos periféricos | Alto | Alto | Dominios sensibles a la privacidad |
| Híbridos | Mixto | Moderado | Alto | Entornos normativos complejos |
Aprendizaje activo y formación eficiente en materia de datos
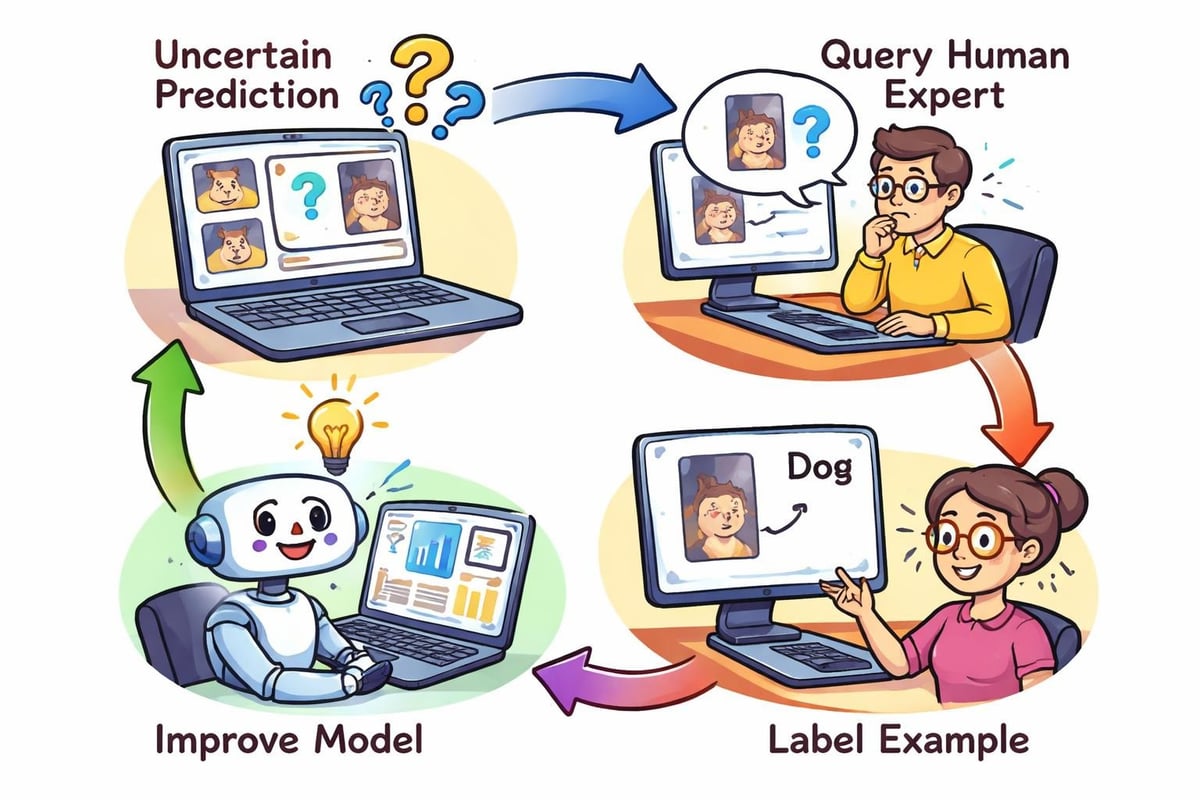
No todos los ejemplos de entrenamiento contribuyen por igual al rendimiento del modelo. El aprendizaje activo selecciona estratégicamente los puntos de datos más informativos para el etiquetado, minimizando el esfuerzo de anotación necesario para alcanzar los niveles de precisión deseados.
Implementación de estrategias de consulta
Las técnicas de aprendizaje activo emplean diversas estrategias para identificar ejemplos valiosos sin etiquetar. El muestreo de incertidumbre selecciona las instancias en las que el modelo muestra menos confianza, mientras que la consulta por comité utiliza el desacuerdo entre varios modelos para identificar muestras informativas.
Estos enfoques resultan especialmente valiosos cuando los costes de etiquetado son elevados o el tiempo de los expertos es limitado. Las imágenes médicas, la clasificación de documentos legales y los ámbitos técnicos especializados se benefician significativamente de los métodos de entrenamiento de aprendizaje automático de IA eficientes en términos de datos, que maximizan el aprendizaje a partir de ejemplos etiquetados mínimos.
Estrategias populares de aprendizaje activo:
- Muestreo de incertidumbre centrado en predicciones ambiguas
- Consulta por comité que aprovecha el desacuerdo entre modelos
- Cambio de modelo esperado que selecciona ejemplos de máximo impacto
- Muestreo de diversidad que garantiza una amplia cobertura del espacio de entrada
- Enfoques híbridos que combinan múltiples criterios de selección
Reducción de los requisitos de anotación
El aprendizaje semisupervisado combina pequeños conjuntos de datos etiquetados con abundantes datos sin etiquetar. El modelo aprende inicialmente a partir de ejemplos etiquetados y, a continuación, utiliza sus predicciones sobre datos sin etiquetar para mejorar de forma iterativa. Este enfoque de bootstrapping amplía la capacidad de entrenamiento más allá de los métodos totalmente supervisados, al tiempo que requiere un esfuerzo de etiquetado sustancialmente menor.
El aprendizaje auto-supervisado lleva la eficiencia de los datos aún más lejos al crear señales de supervisión a partir de los propios datos. El modelado de lenguaje enmascarado, utilizado para entrenar grandes modelos de lenguaje, predice partes ocultas del texto utilizando el contexto circundante. De manera similar, el aprendizaje contrastivo crea supervisión al distinguir ejemplos similares de otros diferentes, lo que permite representaciones potentes sin etiquetas manuales.
Consideraciones éticas y prácticas de entrenamiento responsables
El entrenamiento del aprendizaje automático de la IA conlleva importantes responsabilidades éticas. Los modelos pueden perpetuar inadvertidamente los sesgos presentes en los datos de entrenamiento, lo que da lugar a resultados discriminatorios en aplicaciones de alto riesgo, como la contratación, los préstamos y la justicia penal.
Identificación y mitigación de los sesgos en la formación
Los sesgos se introducen en el entrenamiento del aprendizaje automático de IA a través de múltiples canales. Los datos históricos pueden reflejar discriminaciones pasadas, los métodos de muestreo pueden subrepresentar a determinadas poblaciones y las definiciones de las etiquetas pueden codificar juicios subjetivos. Reconocer estas fuentes es el primer paso para mitigarlos.
Las técnicas para abordar los sesgos incluyen el remuestreo para equilibrar la representación, la reponderación de ejemplos para igualar la influencia y la eliminación de sesgos adversarios que penaliza explícitamente los patrones discriminatorios. Sin embargo, las soluciones técnicas por sí solas resultan insuficientes. Las organizaciones deben establecer marcos de gobernanza que incluyan las perspectivas de las diversas partes interesadas a lo largo del ciclo de vida del desarrollo.
Las investigaciones que revisan las herramientas éticas de la IA y los métodos de implementación ponen de relieve la brecha entre los principios éticos y la implementación práctica. La traducción de valores abstractos en prácticas de formación concretas requiere una atención continua, auditorías periódicas y la voluntad de mejorar los modelos de forma iterativa a medida que surgen problemas.
Garantizar la transparencia y la explicabilidad de los modelos
Los modelos de caja negra que proporcionan predicciones precisas sin explicación suscitan preocupación en los sectores regulados y en las decisiones de alto riesgo. Las técnicas de IA explicables ayudan a las partes interesadas a comprender cómo los modelos llegan a sus conclusiones, lo que genera confianza y permite una supervisión significativa.
Los métodos de explicación independientes del modelo, como LIME y SHAP, funcionan con diferentes algoritmos e identifican qué características influyen más en predicciones específicas. Los mecanismos de atención en las redes neuronales revelan en qué partes de la entrada se centró el modelo. Los modelos intrínsecamente interpretables, como los árboles de decisión y la regresión lineal, sacrifican parte de su capacidad predictiva a cambio de una transparencia total.
Instituciones como el Instituto Kempner para el Estudio de la Inteligencia Natural y Artificial llevan a cabo investigaciones fundamentales sobre los mecanismos de inteligencia que, en última instancia, pueden dar lugar a sistemas de IA más interpretables. Mientras tanto, los profesionales deben equilibrar la precisión, la explicabilidad y las consideraciones éticas al diseñar enfoques de formación.
Aprendizaje continuo y mantenimiento de modelos
La implementación de un modelo entrenado representa el comienzo, más que el final, del ciclo de vida del entrenamiento del aprendizaje automático de la IA. Los entornos del mundo real cambian con el tiempo, lo que provoca que el rendimiento del modelo se degrade a medida que los datos de entrenamiento se vuelven menos representativos de las condiciones actuales.
Supervisión del rendimiento del modelo en producción
La supervisión de la producción realiza un seguimiento de las métricas de rendimiento clave para detectar cuándo es necesario volver a entrenar. La exactitud, la precisión, la recuperación y otras métricas estándar deben evaluarse continuamente con datos nuevos. La deriva conceptual se produce cuando cambia la relación entre las características y los objetivos, mientras que la deriva de datos se produce cuando cambian las distribuciones de entrada, incluso si las relaciones se mantienen estables.
Los sistemas de supervisión automatizados pueden activar alertas cuando el rendimiento se degrada más allá de los umbrales aceptables. Algunas organizaciones implementan lanzamientos por etapas, exponiendo gradualmente las nuevas versiones del modelo a un tráfico cada vez mayor mientras supervisan los problemas. Las pruebas A/B comparan los nuevos modelos con las bases de referencia existentes para garantizar las mejoras antes de la implementación completa.
Los componentes esenciales de la supervisión incluyen:
- Seguimiento de métricas de rendimiento en tiempo real
- Supervisión de la distribución de datos para la detección de desviaciones
- Predicción de la latencia y medición del rendimiento
- Análisis de errores para identificar patrones de fallos sistemáticos
- Recopilación de comentarios de los usuarios finales y las partes interesadas
Implementación de procesos de formación continua
La formación continua automatiza el proceso de actualización de los modelos a medida que se reciben nuevos datos. En lugar de realizar una recapacitación manual periódica, los sistemas incorporan automáticamente nuevos ejemplos, recapacitan los modelos, validan el rendimiento e implementan mejoras cuando se cumplen los umbrales de calidad.
Este enfoque mantiene los modelos actualizados con los patrones en evolución, al tiempo que reduce la intervención manual. Sin embargo, introduce nuevos retos en torno al control de versiones, los procedimientos de reversión y la garantía de una validación suficiente antes de la implementación. Las organizaciones deben establecer prácticas sólidas de MLOps que traten el entrenamiento de modelos con el mismo rigor que el desarrollo de software.
Para los profesionales que desarrollan estas capacidades, explorar los mejores cursos de aprendizaje automático les permite conocer las mejores prácticas del sector y adquirir experiencia práctica con herramientas y plataformas modernas.
Estrategias de formación en IA empresarial
Las organizaciones se enfrentan a retos únicos a la hora de implementar la formación en aprendizaje automático de IA a gran escala. A diferencia de los profesionales individuales que experimentan con modelos, las empresas deben tener en cuenta la gobernanza, el cumplimiento normativo, la colaboración en equipo y la alineación con los objetivos empresariales.
Desarrollo de capacidades de formación interna
El desarrollo de conocimientos especializados internos requiere una inversión estratégica en educación e infraestructura. Las organizaciones deben identificar casos de uso de alto valor en los que la IA pueda tener un impacto comercial cuantificable y, a continuación, formar equipos multifuncionales que combinen conocimientos del sector con habilidades técnicas.
Los programas de aprendizaje estructurados aceleran el desarrollo de capacidades. Los programas de certificación corporativa proporcionan una formación estandarizada que garantiza un conocimiento básico uniforme en todos los equipos. Los proyectos prácticos que aplican técnicas a problemas empresariales reales consolidan el aprendizaje al tiempo que aportan un valor tangible.
Los mecanismos de intercambio de conocimientos, como las comunidades de práctica internas, las presentaciones técnicas periódicas y las normas de documentación, ayudan a distribuir los conocimientos más allá de los profesionales iniciales. Los programas de mentoría emparejan a profesionales experimentados con aquellos que están desarrollando sus habilidades, creando una transferencia de conocimientos sostenible.
Selección de plataformas y herramientas de formación
El panorama tecnológico para la formación en aprendizaje automático con IA sigue expandiéndose rápidamente. Las organizaciones deben evaluar las plataformas en función de sus requisitos específicos, la infraestructura existente y las capacidades del equipo. Las soluciones basadas en la nube ofrecen flexibilidad y escalabilidad, mientras que las implementaciones locales proporcionan un mayor control sobre los datos confidenciales.
Las plataformas gestionadas abstraen la complejidad de la infraestructura, pero pueden introducir dependencia de un proveedor. Los marcos de código abierto proporcionan flexibilidad y transparencia, pero requieren conocimientos más especializados. Los enfoques híbridos combinan plataformas comerciales para cargas de trabajo de producción con herramientas de código abierto para la experimentación y la investigación.
| Tipo de plataforma | Ventajas | Desventajas | Ideal para |
|---|---|---|---|
| Gestión en la nube | Configuración rápida, escalado automático | Costes continuos, posible dependencia | Rápida implementación, cargas de trabajo variables |
| Código abierto | Flexibilidad, sin costes de licencia | Requiere experiencia, autogestionado | Personalización, restricciones presupuestarias |
| Empresa | Soporte, funciones de gobernanza | Alto coste, complejidad | Grandes organizaciones, necesidades de cumplimiento normativo |
| Híbrido | Enfoque equilibrado | Complejidad de integración | Requisitos mixtos |
Tendencias emergentes que dan forma a las metodologías de formación
El campo de la formación en aprendizaje automático con IA sigue evolucionando rápidamente, con nuevas técnicas y enfoques que surgen con regularidad. Mantenerse al día con estos avances ayuda a las organizaciones a mantener sus ventajas competitivas y a adoptar métodos de formación más eficientes.
Modelos básicos y aprendizaje con pocos ejemplos
Los grandes modelos básicos entrenados con conjuntos de datos masivos muestran una notable capacidad para adaptarse a nuevas tareas con un entrenamiento adicional mínimo. El aprendizaje con pocos ejemplos permite a estos modelos funcionar bien en tareas novedosas utilizando solo unos pocos ejemplos, lo que reduce drásticamente los requisitos de datos que históricamente han limitado la adopción de la IA.
Este cambio de paradigma modifica la forma en que las organizaciones abordan el entrenamiento del aprendizaje automático de la IA. En lugar de recopilar miles de ejemplos etiquetados para cada nueva aplicación, los equipos pueden ajustar los modelos preexistentes utilizando pequeños conjuntos de datos. Esta accesibilidad permite a las organizaciones más pequeñas implementar una IA sofisticada sin los recursos que se requerían anteriormente.
Aprendizaje automático y búsqueda de arquitectura neuronal
Las plataformas AutoML automatizan aspectos tradicionalmente manuales del desarrollo de modelos, desde la ingeniería de características hasta la selección de la arquitectura y la optimización de hiperparámetros. Estos sistemas democratizan la IA al permitir que los profesionales con experiencia limitada construyan modelos eficaces, al tiempo que liberan a los profesionales experimentados para que se centren en estrategias de más alto nivel.
La búsqueda de arquitectura neuronal descubre automáticamente las estructuras de red óptimas para tareas específicas. En lugar de basarse en la intuición humana sobre las configuraciones y conexiones de las capas, estos sistemas exploran amplios espacios de arquitectura para identificar diseños superiores. A medida que disminuyen los costes computacionales, es probable que estos enfoques se conviertan en una práctica habitual en los flujos de trabajo de formación en aprendizaje automático de la IA.
Estandarización y mejores prácticas
Los esfuerzos de la industria hacia la estandarización ayudan a establecer marcos comunes para el desarrollo de la IA. La Recomendación Y.3181 de la UIT-T proporciona orientación arquitectónica para integrar el aprendizaje automático en la infraestructura de red, mientras que varios consorcios industriales trabajan en la elaboración de normas de interoperabilidad.
Publicaciones como Machine Learning and Knowledge Extraction difunden los resultados de las investigaciones que sirven de base para las mejores prácticas en constante evolución. A medida que el campo madura, los enfoques normalizados para la validación, las pruebas y la implementación ayudarán a las organizaciones a implementar la IA de forma más fiable y eficiente.
Dominar la formación en aprendizaje automático de IA requiere comprender los conceptos fundamentales, implementar las mejores prácticas y mantenerse al día con las técnicas en rápida evolución. Las organizaciones que invierten estratégicamente en el desarrollo de estas capacidades se posicionan para aprovechar el potencial transformador de la IA, al tiempo que abordan las consideraciones éticas de forma responsable. MammothClub ofrece itinerarios de aprendizaje completos, bootcamps prácticos y programas de certificación corporativa que ayudan a los profesionales y a los equipos a desarrollar rápidamente habilidades prácticas en IA. Con más de 3000 cursos que abarcan desde conceptos básicos hasta técnicas avanzadas, nuestra plataforma ofrece la infraestructura de formación que las organizaciones necesitan para competir eficazmente en la era de la IA.


