La rapida evoluzione dell'intelligenza artificiale ha trasformato il modo in cui le organizzazioni affrontano l'implementazione della tecnologia e lo sviluppo della forza lavoro. Al centro di questa trasformazione c'è l'addestramento dell'apprendimento automatico dell'intelligenza artificiale, un processo fondamentale che consente agli algoritmi di apprendere dai dati e prendere decisioni intelligenti senza una programmazione esplicita. Comprendere i fondamenti dell'addestramento dei modelli di apprendimento automatico è diventato essenziale per i professionisti che cercano di sfruttare appieno il potenziale dell'intelligenza artificiale, che siano data scientist, analisti aziendali o leader tecnologici che guidano iniziative di trasformazione digitale.
Comprendere i fondamenti dell'addestramento dell'apprendimento automatico dell'intelligenza artificiale
L'addestramento dell'apprendimento automatico dell'IA rappresenta il processo sistematico di immissione di dati negli algoritmi per aiutarli a riconoscere modelli, fare previsioni e migliorare le prestazioni nel tempo. Questo concetto fondamentale distingue l'IA moderna dai tradizionali approcci di programmazione basati su regole.
I componenti fondamentali dell'architettura di addestramento
Ogni iniziativa di formazione di successo nell'ambito dell'apprendimento automatico si basa su diversi elementi interconnessi che collaborano per produrre modelli accurati e affidabili. I dati di formazione fungono da base, fornendo esempi dai quali gli algoritmi estraggono modelli e relazioni significativi.
I componenti essenziali della formazione includono:
- Set di dati di formazione con esempi etichettati per l'apprendimento supervisionato
- Selezione dell'algoritmo in base alla complessità del problema e alle caratteristiche dei dati
- Configurazione degli iperparametri per ottimizzare le prestazioni del modello
- Framework di convalida per prevenire il sovradattamento e garantire la generalizzazione
- Infrastruttura computazionale per gestire le esigenze di elaborazione
La qualità dei dati di addestramento influisce direttamente sulle prestazioni del modello, come dimostrato da numerose ricerche. Gli studi che esaminano gli effetti della qualità dei dati sulle prestazioni dell'apprendimento automatico rivelano che incongruenze, distorsioni e incompletezze nei set di dati di addestramento possono compromettere in modo significativo l'accuratezza e l'affidabilità del modello.
Approcci di addestramento supervisionato vs non supervisionato
Paradigmi di apprendimento diversi richiedono metodologie di addestramento distinte. L'apprendimento supervisionato addestra i modelli utilizzando dati etichettati in cui sono note le risposte corrette, consentendo agli algoritmi di apprendere le mappature input-output. Questo approccio domina applicazioni come la classificazione delle immagini, il riconoscimento vocale e l'analisi predittiva.
L'apprendimento non supervisionato, al contrario, scopre modelli nascosti in dati non etichettati senza categorie predeterminate. L'addestramento di modelli non supervisionati comporta la configurazione di algoritmi per identificare cluster, associazioni e anomalie in modo indipendente. L'apprendimento semi-supervisionato e l'apprendimento per rinforzo rappresentano approcci ibridi che combinano elementi di entrambi i paradigmi.
| Paradigma di addestramento | Requisiti dei dati | Applicazioni comuni | Livello di complessità |
|---|---|---|---|
| Supervisionato | Set di dati etichettati | Classificazione, regressione | Moderato |
| Non supervisionato | Dati non etichettati | Clustering, riduzione della dimensionalità | Elevata |
| Semi-supervisionato | Parzialmente etichettato | Classificazione del testo, riconoscimento delle immagini | Alta |
| Rinforzo | Segnali di ricompensa | Giochi, robotica | Molto alto |
Creazione di percorsi formativi efficaci
La creazione di pipeline di formazione solide per l'apprendimento automatico dell'intelligenza artificiale richiede un'attenta pianificazione e un'esecuzione sistematica. La pipeline trasforma i dati grezzi in modelli implementabili attraverso flussi di lavoro strutturati che garantiscono coerenza e riproducibilità.
Preparazione dei dati e feature engineering
La preparazione dei dati richiede circa l'80% del tempo nei tipici progetti di machine learning. Questa fase cruciale comporta la raccolta dei dati rilevanti, la pulizia delle incongruenze, la gestione dei valori mancanti e la trasformazione delle caratteristiche in formati che gli algoritmi possono elaborare in modo efficace.
L'ingegneria delle caratteristiche rappresenta l'arte di selezionare e creare variabili che rappresentino al meglio i modelli sottostanti. In questo caso, la competenza nel settore diventa preziosa, poiché la comprensione del contesto aziendale aiuta a identificare quali caratteristiche influenzeranno maggiormente le previsioni del modello. Per i professionisti che desiderano sviluppare queste competenze, l'esplorazione di percorsi di apprendimento completi sull'IA e l'apprendimento automatico fornisce una guida strutturata attraverso questi concetti tecnici.
Fasi critiche della preparazione dei dati:
- Raccolta di dati da più fonti e formati
- Pulizia dei dati per rimuovere i duplicati e correggere gli errori
- Ridimensionamento delle caratteristiche per normalizzare gli intervalli di valori
- Selezione delle caratteristiche per identificare le variabili più predittive
- Suddivisione dei dati in set di addestramento, convalida e test
Selezione del modello e progettazione dell'architettura
La scelta degli algoritmi appropriati dipende dalle caratteristiche del problema, dal volume dei dati e dai requisiti di prestazione. Gli alberi decisionali eccellono in termini di interpretabilità, le reti neurali gestiscono relazioni non lineari complesse e i metodi ensemble combinano più modelli per una maggiore accuratezza.
Le architetture di deep learning introducono ulteriore complessità nell'addestramento dell'apprendimento automatico dell'IA. Le reti neurali convoluzionali elaborano i dati visivi in modo efficiente, le reti ricorrenti gestiscono le informazioni sequenziali e le architetture dei trasformatori hanno rivoluzionato l'elaborazione del linguaggio naturale. Ogni architettura richiede strategie di addestramento e risorse computazionali specifiche, in particolare quando si lavora con GPU ottimizzate per l'addestramento dell'IA.
Tecniche di addestramento avanzate e ottimizzazione
L'addestramento moderno dell'apprendimento automatico dell'IA incorpora tecniche sofisticate che accelerano l'apprendimento, migliorano la precisione e riducono i costi computazionali. Questi metodi avanzati distinguono i modelli adeguati da quelli eccezionali.
Apprendimento trasferito e modelli pre-addestrati
Il transfer learning sfrutta le conoscenze acquisite dai modelli addestrati su grandi set di dati per avviare rapidamente l'addestramento su attività correlate. Anziché addestrare i modelli da zero, i professionisti ottimizzano i modelli pre-addestrati utilizzando set di dati più piccoli e specifici per l'attività. Questo approccio riduce drasticamente i tempi di addestramento e i requisiti di dati, migliorando spesso le prestazioni finali del modello.
La proliferazione dei modelli pre-addestrati ha democratizzato l'accesso alle funzionalità AI all'avanguardia. Le organizzazioni possono ora implementare soluzioni sofisticate senza le enormi risorse computazionali precedentemente necessarie. Tuttavia, comprendere quando e come applicare il transfer learning richiede solide basi teoriche che i corsi di AI per principianti possono fornire.
Ottimizzazione dei modelli e regolazione degli iperparametri
Gli iperparametri controllano il processo di apprendimento stesso piuttosto che essere appresi dai dati. Il tasso di apprendimento, la dimensione del batch, il numero di livelli e la forza di regolarizzazione hanno tutti un impatto significativo sui risultati dell'addestramento. La regolazione sistematica degli iperparametri spesso separa i risultati mediocri dalle prestazioni rivoluzionarie.
Le strategie di ottimizzazione comuni includono:
- Ricerca a griglia che esamina tutte le combinazioni di parametri
- Ricerca casuale che campiona in modo efficiente lo spazio dei parametri
- Ottimizzazione bayesiana utilizzando modelli probabilistici
- Piattaforme di apprendimento automatico (AutoML)
- Ricerca dell'architettura neurale per il deep learning
Secondo l'Artificial Intelligence Index Report 2024, le organizzazioni adottano sempre più spesso approcci automatizzati per l'ottimizzazione degli iperparametri, riducendo lo sforzo manuale tradizionalmente richiesto e scoprendo configurazioni superiori che i professionisti umani potrebbero trascurare.
Approcci di formazione distribuiti e federati
Con l'aumentare delle dimensioni dei set di dati e dei modelli, la formazione su singola macchina diventa impraticabile. La formazione distribuita parallelizza il calcolo su più processori o macchine, consentendo alle organizzazioni di formare modelli che altrimenti sarebbero impossibili.
Scalabilità della formazione attraverso l'infrastruttura
Le piattaforme cloud come Amazon SageMaker forniscono ambienti gestiti per l'addestramento distribuito dell'apprendimento automatico. Queste piattaforme astraggono la complessità dell'infrastruttura, distribuendo automaticamente i carichi di lavoro e gestendo l'allocazione delle risorse. Il parallelismo dei dati suddivide i dati di addestramento su più lavoratori, mentre il parallelismo dei modelli divide il modello stesso quando supera la capacità di memoria di un singolo dispositivo.
Le decisioni relative all'infrastruttura hanno un impatto significativo sull'efficienza e sui costi della formazione. Le organizzazioni devono bilanciare i requisiti di prestazioni con i vincoli di budget, tenendo conto di fattori quali i tipi di processori, le configurazioni di memoria e la larghezza di banda della rete. Comprendere questi compromessi aiuta i leader tecnologici a effettuare investimenti informati nell'infrastruttura.
Apprendimento federato per la formazione che preserva la privacy
L'apprendimento federato consente la formazione collaborativa dei modelli senza centralizzare i dati sensibili. I dispositivi addestrano i modelli locali sui propri dati, condividendo solo gli aggiornamenti dei modelli anziché le informazioni grezze. Il server centrale aggrega questi aggiornamenti per migliorare il modello globale, che viene ridistribuito per un'ulteriore formazione locale.
La ricerca sui framework di apprendimento federato ha accelerato lo sviluppo di tecniche di formazione di machine learning AI che preservano la privacy. Questo approccio è particolarmente vantaggioso per il settore sanitario, finanziario e altri settori in cui le normative sulla privacy dei dati limitano la condivisione delle informazioni. Il Munich Center for Machine Learning ricerca attivamente approcci federati insieme ad altre metodologie di formazione all'avanguardia.
| Approccio di addestramento | Posizione dei dati | Livello di privacy | Complessità | Casi d'uso ottimali |
|---|---|---|---|---|
| Centralizzato | Server singolo | Basso | Basso | Applicazioni non sensibili |
| Distribuito | Server multipli | Basso | Moderato | Formazione su larga scala |
| Federato | Dispositivi periferici | Elevato | Elevato | Domini sensibili alla privacy |
| Ibrido | Misto | Moderato | Elevato | Contesti normativi complessi |
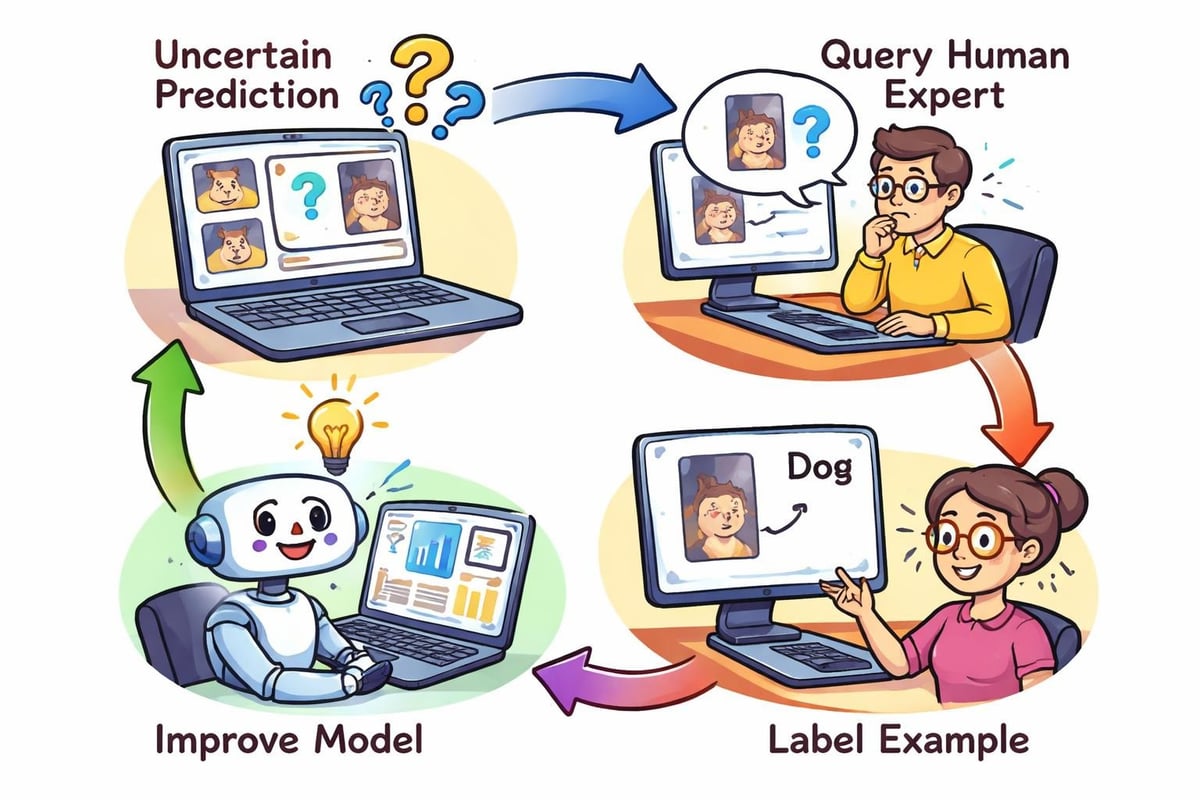
Apprendimento attivo e formazione efficiente in termini di dati
Non tutti gli esempi di formazione contribuiscono allo stesso modo alle prestazioni del modello. L'apprendimento attivo seleziona strategicamente i punti dati più informativi per l'etichettatura, riducendo al minimo lo sforzo di annotazione necessario per raggiungere i livelli di accuratezza desiderati.
Implementazione di strategie di query
Le tecniche di apprendimento attivo utilizzano varie strategie per identificare esempi non etichettati di valore. Il campionamento dell'incertezza seleziona le istanze in cui il modello mostra la minore affidabilità, mentre la query-by-committee utilizza il disaccordo tra più modelli per identificare campioni informativi.
Questi approcci si rivelano particolarmente preziosi quando i costi di etichettatura sono elevati o il tempo a disposizione degli esperti è limitato. L'imaging medico, la classificazione dei documenti legali e i settori tecnici specializzati traggono notevoli vantaggi dai metodi di addestramento dell'apprendimento automatico basati sull'intelligenza artificiale efficienti dal punto di vista dei dati, che massimizzano l'apprendimento da esempi etichettati minimi.
Strategie di apprendimento attivo più diffuse:
- Campionamento dell'incertezza incentrato su previsioni ambigue
- Query-by-committee che sfrutta il disaccordo tra i modelli
- Modifica prevista del modello che seleziona esempi di massimo impatto
- Campionamento della diversità che garantisce un'ampia copertura dello spazio di input
- Approcci ibridi che combinano criteri di selezione multipli
Riduzione dei requisiti di annotazione
L'apprendimento semi-supervisionato combina piccoli set di dati etichettati con abbondanti dati non etichettati. Il modello apprende inizialmente dagli esempi etichettati, quindi utilizza le sue previsioni sui dati non etichettati per migliorare in modo iterativo. Questo approccio di bootstrapping estende la capacità di addestramento oltre i metodi completamente supervisionati, richiedendo al contempo uno sforzo di etichettatura notevolmente inferiore.
L'apprendimento auto-supervisionato migliora ulteriormente l'efficienza dei dati creando segnali di supervisione dai dati stessi. La modellazione linguistica mascherata, utilizzata per addestrare modelli linguistici di grandi dimensioni, prevede le parti nascoste del testo utilizzando il contesto circostante. Allo stesso modo, l'apprendimento contrastivo crea supervisione distinguendo esempi simili da quelli dissimili, consentendo rappresentazioni potenti senza etichette manuali.
Considerazioni etiche e pratiche di addestramento responsabili
L'addestramento dell'apprendimento automatico dell'IA comporta significative responsabilità etiche. I modelli possono inavvertitamente perpetuare i pregiudizi presenti nei dati di addestramento, portando a risultati discriminatori in applicazioni ad alto rischio come l'assunzione, i prestiti e la giustizia penale.
Identificazione e mitigazione dei pregiudizi nella formazione
I pregiudizi entrano nella formazione sull'apprendimento automatico dell'intelligenza artificiale attraverso molteplici canali. I dati storici possono riflettere discriminazioni passate, i metodi di campionamento possono sottorappresentare determinate popolazioni e le definizioni delle etichette possono codificare giudizi soggettivi. Riconoscere queste fonti rappresenta il primo passo verso la mitigazione.
Le tecniche per affrontare i pregiudizi includono il ricampionamento per bilanciare la rappresentanza, la riponderazione degli esempi per equalizzare l'influenza e la rimozione dei pregiudizi avversari che penalizza esplicitamente i modelli discriminatori. Tuttavia, le soluzioni tecniche da sole si dimostrano insufficienti. Le organizzazioni devono stabilire quadri di governance che includano le diverse prospettive delle parti interessate durante tutto il ciclo di vita dello sviluppo.
La ricerca che esamina gli strumenti etici dell'IA e i metodi di implementazione evidenzia il divario tra i principi etici e l'implementazione pratica. Tradurre valori astratti in pratiche di formazione concrete richiede attenzione continua, audit regolari e la volontà di migliorare iterativamente i modelli man mano che emergono i problemi.
Garantire la trasparenza e la spiegabilità dei modelli
I modelli black-box che forniscono previsioni accurate senza spiegazioni sollevano preoccupazioni nei settori regolamentati e nelle decisioni ad alto rischio. Le tecniche di IA spiegabili aiutano le parti interessate a comprendere come i modelli giungono alle conclusioni, creando fiducia e consentendo una supervisione significativa.
Metodi di spiegazione indipendenti dal modello come LIME e SHAP funzionano con diversi algoritmi, identificando quali caratteristiche hanno influenzato maggiormente previsioni specifiche. I meccanismi di attenzione nelle reti neurali rivelano su quali parti dell'input si è concentrato il modello. Modelli intrinsecamente interpretabili come gli alberi decisionali e la regressione lineare sacrificano parte della loro capacità predittiva a favore di una trasparenza completa.
Istituzioni come il Kempner Institute for the Study of Natural and Artificial Intelligence conducono ricerche fondamentali sui meccanismi di intelligenza che potrebbero portare alla creazione di sistemi di IA più interpretabili. Nel frattempo, i professionisti devono trovare un equilibrio tra accuratezza, spiegabilità e considerazioni etiche nella progettazione degli approcci di formazione.
Apprendimento continuo e manutenzione dei modelli
L'implementazione di un modello addestrato rappresenta l'inizio piuttosto che la fine del ciclo di vita dell'addestramento dell'apprendimento automatico dell'IA. Gli ambienti reali cambiano nel tempo, causando un deterioramento delle prestazioni del modello man mano che i dati di addestramento diventano meno rappresentativi delle condizioni attuali.
Monitoraggio delle prestazioni del modello in produzione
Il monitoraggio della produzione tiene traccia delle metriche chiave delle prestazioni per rilevare quando è necessario un nuovo addestramento. L'accuratezza, la precisione, il richiamo e altre metriche standard devono essere valutate continuamente su dati aggiornati. Il concept drift si verifica quando cambia la relazione tra caratteristiche e obiettivi, mentre il data drift si verifica quando le distribuzioni degli input cambiano anche se le relazioni rimangono stabili.
I sistemi di monitoraggio automatizzati possono attivare avvisi quando le prestazioni si riducono oltre le soglie accettabili. Alcune organizzazioni implementano rollout graduali, esponendo gradualmente le nuove versioni dei modelli a un traffico crescente mentre monitorano eventuali problemi. I test A/B confrontano i nuovi modelli con le linee di base esistenti per garantire miglioramenti prima della distribuzione completa.
I componenti essenziali del monitoraggio includono:
- Monitoraggio in tempo reale delle metriche delle prestazioni
- Monitoraggio della distribuzione dei dati per il rilevamento delle derive
- Misurazione della latenza di previsione e della velocità effettiva
- Analisi degli errori per identificare modelli di guasti sistematici
- Raccolta di feedback dagli utenti finali e dalle parti interessate
Implementazione di pipeline di formazione continua
La formazione continua automatizza il processo di aggiornamento dei modelli man mano che arrivano nuovi dati. Anziché ricorrere a periodici aggiornamenti manuali, i sistemi incorporano automaticamente nuovi esempi, aggiornano i modelli, convalidano le prestazioni e implementano miglioramenti quando vengono raggiunte le soglie di qualità.
Questo approccio mantiene i modelli aggiornati con modelli in evoluzione, riducendo al contempo l'intervento manuale. Tuttavia, introduce nuove sfide relative al controllo delle versioni, alle procedure di rollback e alla garanzia di una convalida sufficiente prima dell'implementazione. Le organizzazioni devono stabilire solide pratiche MLOps che trattino la formazione dei modelli con lo stesso rigore dello sviluppo del software.
Per i professionisti che sviluppano queste capacità, esplorare i migliori corsi di machine learning offre l'opportunità di conoscere le migliori pratiche del settore e di acquisire esperienza pratica con strumenti e piattaforme moderne.
Strategie di formazione sull'IA aziendale
Le organizzazioni devono affrontare sfide uniche quando implementano la formazione sull'apprendimento automatico su larga scala. A differenza dei singoli professionisti che sperimentano i modelli, le imprese devono considerare la governance, la conformità, la collaborazione tra i team e l'allineamento con gli obiettivi aziendali.
Sviluppo di capacità di formazione interne
Lo sviluppo di competenze interne richiede investimenti strategici nell'istruzione e nelle infrastrutture. Le organizzazioni dovrebbero identificare casi d'uso di alto valore in cui l'IA può avere un impatto misurabile sul business, quindi costituire team interfunzionali che combinino conoscenze di settore e competenze tecniche.
I programmi di apprendimento strutturati accelerano lo sviluppo delle capacità. I programmi di certificazione aziendale forniscono una formazione standardizzata che garantisce conoscenze di base coerenti tra i team. I progetti pratici che applicano le tecniche a problemi aziendali reali consolidano l'apprendimento fornendo al contempo un valore tangibile.
Meccanismi di condivisione delle conoscenze come comunità di pratica interne, presentazioni tecniche regolari e standard di documentazione aiutano a distribuire le competenze oltre i professionisti iniziali. I programmi di mentoring accoppiano professionisti esperti con coloro che stanno sviluppando competenze, creando un trasferimento di conoscenze sostenibile.
Selezione di piattaforme e strumenti di formazione
Il panorama tecnologico per la formazione sull'apprendimento automatico dell'intelligenza artificiale continua ad espandersi rapidamente. Le organizzazioni devono valutare le piattaforme in base ai propri requisiti specifici, all'infrastruttura esistente e alle capacità del team. Le soluzioni basate su cloud offrono flessibilità e scalabilità, mentre le implementazioni in loco garantiscono un maggiore controllo sui dati sensibili.
Le piattaforme gestite semplificano la complessità dell'infrastruttura, ma possono introdurre il vendor lock-in. I framework open source offrono flessibilità e trasparenza, ma richiedono competenze più specializzate. Gli approcci ibridi combinano piattaforme commerciali per i carichi di lavoro di produzione con strumenti open source per la sperimentazione e la ricerca.
| Tipo di piattaforma | Vantaggi | Svantaggi | Ideale per |
|---|---|---|---|
| Gestione cloud | Configurazione rapida, scalabilità automatica | Costi ricorrenti, potenziale lock-in | Implementazione rapida, carichi di lavoro variabili |
| Open Source | Flessibilità, nessun costo di licenza | Richiede competenze specifiche, autogestito | Personalizzazione, vincoli di budget |
| Aziendale | Supporto, funzionalità di governance | Costo elevato, complessità | Grandi organizzazioni, esigenze di conformità |
| Ibrido | Approccio equilibrato | Complessità di integrazione | Requisiti misti |
Tendenze emergenti che influenzano le metodologie di formazione
Il campo della formazione sull'apprendimento automatico dell'intelligenza artificiale continua a evolversi rapidamente, con nuove tecniche e approcci che emergono regolarmente. Rimanere al passo con questi sviluppi aiuta le organizzazioni a mantenere vantaggi competitivi e ad adottare metodi di formazione più efficienti.
Modelli di base e apprendimento con pochi esempi
I grandi modelli di base addestrati su enormi set di dati mostrano notevoli capacità di adattarsi a nuovi compiti con una formazione aggiuntiva minima. L'apprendimento con pochi esempi consente a questi modelli di funzionare bene su compiti nuovi utilizzando solo una manciata di esempi, riducendo drasticamente i requisiti di dati che storicamente hanno limitato l'adozione dell'intelligenza artificiale.
Questo cambiamento di paradigma modifica il modo in cui le organizzazioni affrontano la formazione nel campo dell'apprendimento automatico basato sull'intelligenza artificiale. Anziché raccogliere migliaia di esempi etichettati per ogni nuova applicazione, i team possono mettere a punto modelli preesistenti utilizzando piccoli set di dati. Questa accessibilità consente alle organizzazioni più piccole di implementare un'intelligenza artificiale sofisticata senza le risorse precedentemente necessarie.
Apprendimento automatico e ricerca dell'architettura neurale
Le piattaforme AutoML automatizzano gli aspetti tradizionalmente manuali dello sviluppo dei modelli, dall'ingegneria delle caratteristiche alla selezione dell'architettura fino all'ottimizzazione degli iperparametri. Questi sistemi democratizzano l'intelligenza artificiale consentendo ai professionisti con competenze limitate di costruire modelli efficaci, mentre quelli più esperti possono concentrarsi su strategie di livello superiore.
La ricerca dell'architettura neurale individua automaticamente le strutture di rete ottimali per compiti specifici. Anziché affidarsi all'intuizione umana riguardo alle configurazioni e alle connessioni dei livelli, questi sistemi esplorano vasti spazi architettonici per identificare progetti superiori. Con la diminuzione dei costi di calcolo, questi approcci diventeranno probabilmente una pratica standard nei flussi di lavoro di formazione dell'apprendimento automatico dell'IA.
Standardizzazione e best practice
Gli sforzi del settore verso la standardizzazione contribuiscono a stabilire quadri comuni per lo sviluppo dell'IA. La raccomandazione ITU-T Y.3181 fornisce una guida architettonica per l'integrazione dell'apprendimento automatico nell'infrastruttura di rete, mentre vari consorzi industriali lavorano per definire standard di interoperabilità.
Pubblicazioni come Machine Learning and Knowledge Extraction diffondono i risultati della ricerca che informano le migliori pratiche in evoluzione. Man mano che il settore matura, approcci standardizzati alla convalida, al collaudo e all'implementazione aiuteranno le organizzazioni a implementare l'IA in modo più affidabile ed efficiente.
Padroneggiare la formazione sull'apprendimento automatico dell'IA richiede la comprensione dei concetti fondamentali, l'implementazione delle migliori pratiche e l'aggiornamento costante sulle tecniche in rapida evoluzione. Le organizzazioni che investono strategicamente nello sviluppo di queste capacità si posizionano in modo da sfruttare il potenziale trasformativo dell'IA, affrontando al contempo le considerazioni etiche in modo responsabile. MammothClub offre percorsi di apprendimento completi, bootcamp pratici e programmi di certificazione aziendale che aiutano i professionisti e i team a sviluppare rapidamente competenze pratiche nell'ambito dell'IA. Con oltre 3.000 corsi che coprono tutto, dai concetti fondamentali alle tecniche avanzate, la nostra piattaforma fornisce l'infrastruttura di formazione necessaria alle organizzazioni per competere efficacemente nell'era dell'IA.


