Szybki rozwój sztucznej inteligencji zmienił podejście organizacji do wdrażania technologii i rozwoju kadr. U podstaw tej transformacji leży szkolenie w zakresie uczenia maszynowego AI, kluczowy proces, który umożliwia algorytmom uczenie się na podstawie danych i podejmowanie inteligentnych decyzji bez wyraźnego programowania. Zrozumienie podstaw szkolenia modeli uczenia maszynowego stało się niezbędne dla profesjonalistów pragnących w pełni wykorzystać potencjał AI, niezależnie od tego, czy są to naukowcy zajmujący się danymi, analitycy biznesowi, czy liderzy technologiczni kierujący inicjatywami transformacji cyfrowej.
Zrozumienie podstaw szkolenia w zakresie uczenia maszynowego AI
Szkolenie w zakresie uczenia maszynowego AI to systematyczny proces wprowadzania danych do algorytmów, aby pomóc im rozpoznawać wzorce, tworzyć prognozy i z czasem poprawiać wydajność. Ta podstawowa koncepcja odróżnia nowoczesną sztuczną inteligencję od tradycyjnych podejść programistycznych opartych na regułach.
Podstawowe elementy architektury szkolenia
Każda udana inicjatywa szkoleniowa w zakresie uczenia maszynowego opiera się na kilku powiązanych ze sobą elementach, które współdziałają w celu stworzenia dokładnych i niezawodnych modeli. Dane szkoleniowe stanowią podstawę, dostarczając przykładów, z których algorytmy wyodrębniają znaczące wzorce i relacje.
Podstawowe elementy szkolenia obejmują:
- Zbiory danych szkoleniowych z oznaczonymi przykładami do uczenia nadzorowanego
- Wybór algorytmu w oparciu o złożoność problemu i charakterystykę danych
- Konfiguracja hiperparametrów w celu optymalizacji wydajności modelu
- Struktury walidacyjne zapobiegające nadmiernemu dopasowaniu i zapewniające uogólnienie
- Infrastruktura obliczeniowa do obsługi wymagań przetwarzania
Jak konsekwentnie wykazują badania, jakość danych szkoleniowych ma bezpośredni wpływ na wydajność modelu. Badania dotyczące wpływu jakości danych na wydajność uczenia maszynowego pokazują, że niespójności, tendencyjność i niekompletność zbiorów danych szkoleniowych mogą znacznie obniżyć dokładność i niezawodność modelu.
Podejścia do szkolenia nadzorowanego i nienadzorowanego
Różne paradygmaty uczenia wymagają różnych metodologii szkolenia. Uczenie nadzorowane szkoli modele przy użyciu danych oznaczonych, w przypadku których znane są prawidłowe odpowiedzi, umożliwiając algorytmom naukę mapowania danych wejściowych i wyjściowych. Podejście to dominuje w zastosowaniach takich jak klasyfikacja obrazów, rozpoznawanie mowy i analityka predykcyjna.
Uczenie się bez nadzoru natomiast odkrywa ukryte wzorce w danych nieoznaczonych bez wcześniej określonych kategorii. Szkolenie modeli bez nadzoru polega na konfiguracji algorytmów w celu niezależnej identyfikacji klastrów, powiązań i anomalii. Uczenie się półnadzorowane i wzmacniające stanowią podejścia hybrydowe, które łączą elementy obu paradygmatów.
| Paradygmat szkolenia | Wymagania dotyczące danych | Typowe zastosowania | Poziom złożoności |
|---|---|---|---|
| Nadzorowane | Oznaczone zbiory danych | Klasyfikacja, regresja | Umiarkowany |
| Nienadzorowany | Niezaznaczone dane | Klasteryzacja, redukcja wymiarowości | Wysoka |
| Częściowo nadzorowane | Częściowo oznaczone | Klasyfikacja tekstu, rozpoznawanie obrazów | Wysoka |
| Wzmocnienie | Sygnały nagrody | Gry, robotyka | Bardzo wysokie |
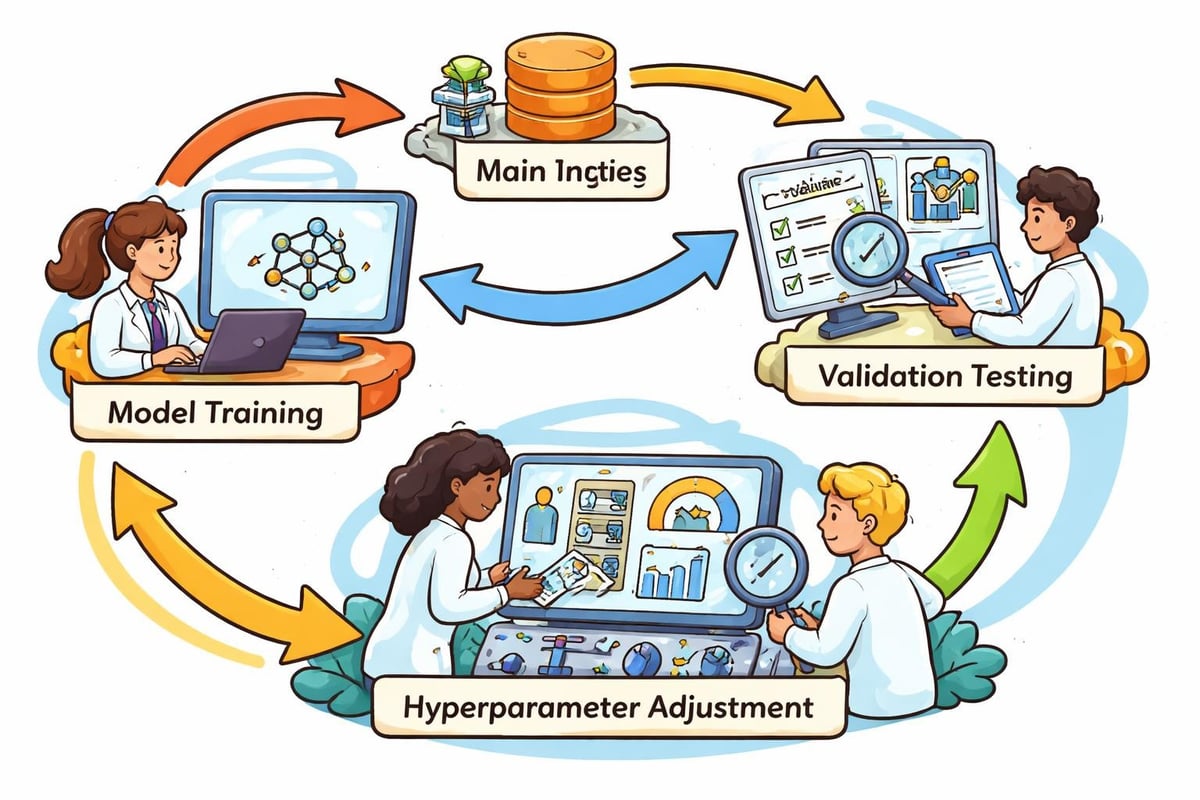
Budowanie skutecznych ścieżek szkoleniowych
Stworzenie solidnych ścieżek szkoleniowych w zakresie uczenia maszynowego wymaga starannego planowania i systematycznej realizacji. Ścieżka przekształca surowe dane w modele gotowe do wdrożenia poprzez ustrukturyzowane przepływy pracy, które zapewniają spójność i powtarzalność.
Przygotowanie danych i inżynieria cech
Przygotowanie danych zajmuje około 80% czasu w typowych projektach uczenia maszynowego. Ten kluczowy etap obejmuje gromadzenie odpowiednich danych, usuwanie niespójności, obsługę brakujących wartości oraz przekształcanie cech w formaty, które algorytmy mogą skutecznie przetwarzać.
Inżynieria cech to sztuka wybierania i tworzenia zmiennych, które najlepiej odzwierciedlają podstawowe wzorce. Nieoceniona jest tu wiedza specjalistyczna w danej dziedzinie, ponieważ zrozumienie kontekstu biznesowego pomaga zidentyfikować cechy, które będą miały największy wpływ na prognozy modelu. Specjaliści pragnący rozwinąć te umiejętności mogą skorzystać z kompleksowych ścieżek edukacyjnych dotyczących sztucznej inteligencji i uczenia maszynowego, które zapewniają uporządkowane wytyczne dotyczące tych koncepcji technicznych.
Kluczowe etapy przygotowania danych:
- Gromadzenie danych z wielu źródeł i w różnych formatach
- Czyszczenie danych w celu usunięcia duplikatów i poprawienia błędów
- Skalowanie cech w celu normalizacji zakresów wartości
- Wybór cech w celu zidentyfikowania zmiennych o największej wartości predykcyjnej
- Podział danych na zestawy szkoleniowe, walidacyjne i testowe
Wybór modelu i projekt architektury
Wybór odpowiednich algorytmów zależy od charakterystyki problemu, ilości danych i wymagań dotyczących wydajności. Drzewa decyzyjne wyróżniają się interpretowalnością, sieci neuronowe radzą sobie ze złożonymi relacjami nieliniowymi, a metody zespołowe łączą wiele modeli w celu zwiększenia dokładności.
Architektury głębokiego uczenia się wprowadzają dodatkową złożoność do szkolenia sztucznej inteligencji w zakresie uczenia maszynowego. Sieci neuronowe konwolucyjne efektywnie przetwarzają dane wizualne, sieci rekurencyjne obsługują informacje sekwencyjne, a architektury transformatorowe zrewolucjonizowały przetwarzanie języka naturalnego. Każda architektura wymaga określonych strategii szkoleniowych i zasobów obliczeniowych, szczególnie w przypadku pracy z procesorami graficznymi zoptymalizowanymi pod kątem szkolenia sztucznej inteligencji.
Zaawansowane techniki szkolenia i optymalizacja
Nowoczesne szkolenia w zakresie uczenia maszynowego AI wykorzystują zaawansowane techniki, które przyspieszają naukę, poprawiają dokładność i zmniejszają koszty obliczeniowe. Te zaawansowane metody oddzielają modele odpowiednie od tych wyjątkowych.
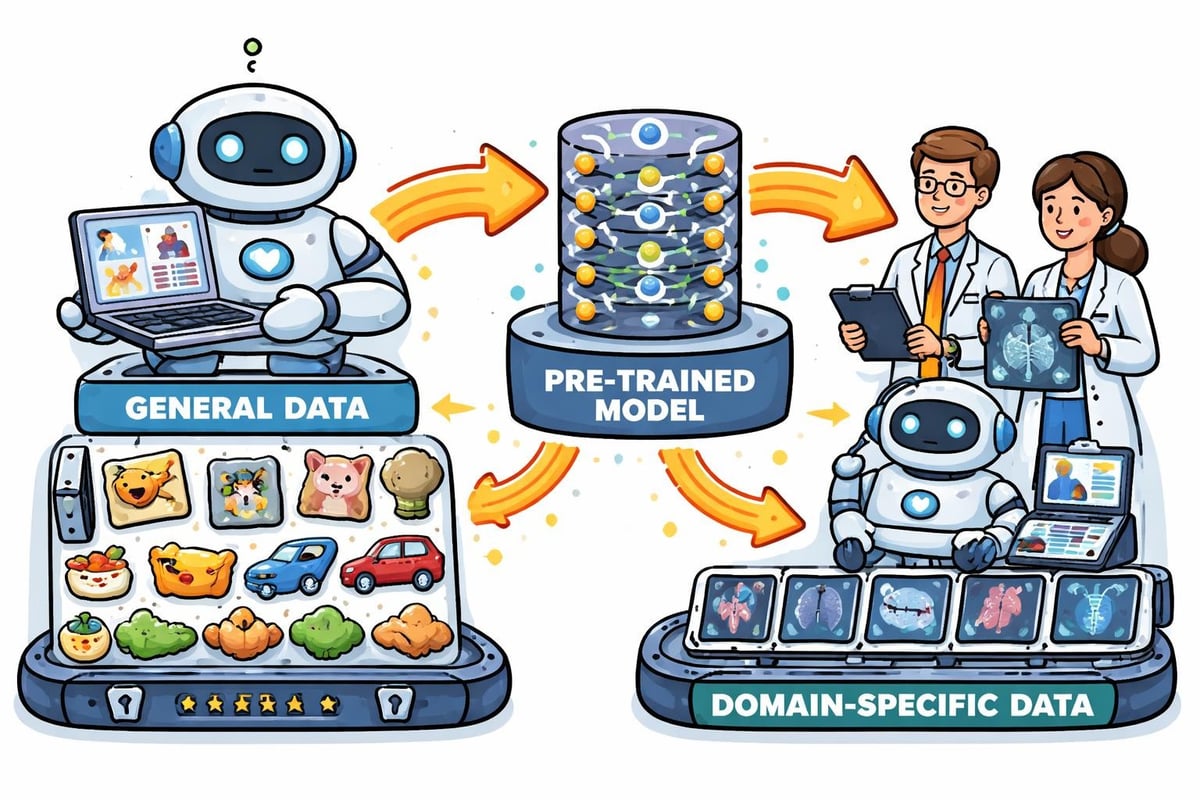
Uczenie transferowe i wstępnie wyszkolone modele
Uczenie transferowe wykorzystuje wiedzę z modeli przeszkolonych na dużych zbiorach danych, aby przyspieszyć szkolenie w zakresie powiązanych zadań. Zamiast szkolić od podstaw, praktycy dostosowują wstępnie przeszkolone modele przy użyciu mniejszych, specyficznych dla zadania zbiorów danych. Takie podejście znacznie skraca czas szkolenia i zmniejsza wymagania dotyczące danych, często poprawiając jednocześnie wydajność końcowego modelu.
Rozpowszechnienie wstępnie wyszkolonych modeli zdemokratyzowało dostęp do najnowocześniejszych możliwości sztucznej inteligencji. Organizacje mogą teraz wdrażać zaawansowane rozwiązania bez konieczności posiadania ogromnych zasobów obliczeniowych, które były wcześniej wymagane. Jednak zrozumienie, kiedy i jak stosować transfer wiedzy, wymaga solidnych podstaw teoretycznych, które mogą zapewnić kursy dla początkujących w zakresie sztucznej inteligencji.
Dostosowywanie hiperparametrów i optymalizacja modeli
Hiperparametry kontrolują sam proces uczenia się, a nie są uczone na podstawie danych. Tempo uczenia się, wielkość partii, liczba warstw i siła regularyzacji mają znaczący wpływ na wyniki szkolenia. Systematyczne dostrajanie hiperparametrów często odróżnia przeciętne wyniki od przełomowych osiągnięć.
Typowe strategie optymalizacji obejmują:
- Wyszukiwanie siatkowe sprawdzające wszystkie kombinacje parametrów
- Losowe przeszukiwanie, które efektywnie bada przestrzeń parametrów
- Optymalizacja bayesowska z wykorzystaniem modeli probabilistycznych
- Platformy automatycznego uczenia maszynowego (AutoML)
- Wyszukiwanie architektury neuronowej dla głębokiego uczenia się
Według raportu Artificial Intelligence Index Report 2024 organizacje coraz częściej stosują zautomatyzowane podejście do optymalizacji hiperparametrów, zmniejszając nakład pracy ręcznej wymaganej tradycyjnie, a jednocześnie odkrywając lepsze konfiguracje, które mogłyby zostać przeoczone przez praktyków.
Rozproszone i federacyjne podejścia do szkolenia
Wraz ze wzrostem rozmiarów zbiorów danych i modeli szkolenie na jednym komputerze staje się niepraktyczne. Szkolenie rozproszone umożliwia równoległe przetwarzanie danych na wielu procesorach lub komputerach, dzięki czemu organizacje mogą szkolić modele, które w innym przypadku byłyby niemożliwe do zrealizowania.
Skalowanie szkolenia w całej infrastrukturze
Platformy chmurowe, takie jak Amazon SageMaker, zapewniają zarządzane środowiska do rozproszonego szkolenia sztucznej inteligencji w zakresie uczenia maszynowego. Platformy te abstrahują złożoność infrastruktury, automatycznie rozdzielając obciążenia i zarządzając alokacją zasobów. Równoległość danych dzieli dane szkoleniowe między wiele urządzeń roboczych, natomiast równoległość modeli dzieli sam model, gdy przekracza on pojemność pamięci pojedynczego urządzenia.
Decyzje dotyczące infrastruktury mają znaczący wpływ na wydajność i koszty szkolenia. Organizacje muszą zrównoważyć wymagania dotyczące wydajności z ograniczeniami budżetowymi, biorąc pod uwagę takie czynniki, jak typy procesorów, konfiguracje pamięci i przepustowość sieci. Zrozumienie tych kompromisów pomaga liderom technologicznym w podejmowaniu świadomych inwestycji w infrastrukturę.
Federacyjne uczenie się w celu zachowania prywatności podczas szkolenia
Federacyjne uczenie umożliwia wspólne szkolenie modeli bez centralizacji wrażliwych danych. Urządzenia szkolą lokalne modele na podstawie swoich danych, udostępniając tylko aktualizacje modeli, a nie surowe informacje. Centralny serwer agreguje te aktualizacje w celu ulepszenia globalnego modelu, który jest ponownie dystrybuowany do dalszego szkolenia lokalnego.
Badania nad ramami federacyjnego uczenia przyspieszyły rozwój technik szkolenia sztucznej inteligencji z zachowaniem prywatności. Podejście to jest szczególnie korzystne dla sektora opieki zdrowotnej, finansów i innych sektorów, w których przepisy dotyczące prywatności danych ograniczają wymianę informacji. Centrum Uczenia Maszynowego w Monachium aktywnie bada podejścia federacyjne wraz z innymi najnowocześniejszymi metodami szkolenia.
| Podejście szkoleniowe | Lokalizacja danych | Poziom prywatności | Złożoność | Najlepsze przykłady zastosowań |
|---|---|---|---|---|
| Scentralizowane | Pojedynczy serwer | Niski | Niski | Aplikacje niewymagające szczególnej ochrony |
| Rozproszone | Wiele serwerów | Niski | Umiarkowane | Szkolenia na dużą skalę |
| Federacyjne | Urządzenia brzegowe | Wysokie | Wysoki | Domeny wrażliwe na prywatność |
| Hybrydowe | Mieszane | Umiarkowane | Wysoki | Złożone otoczenie regulacyjne |
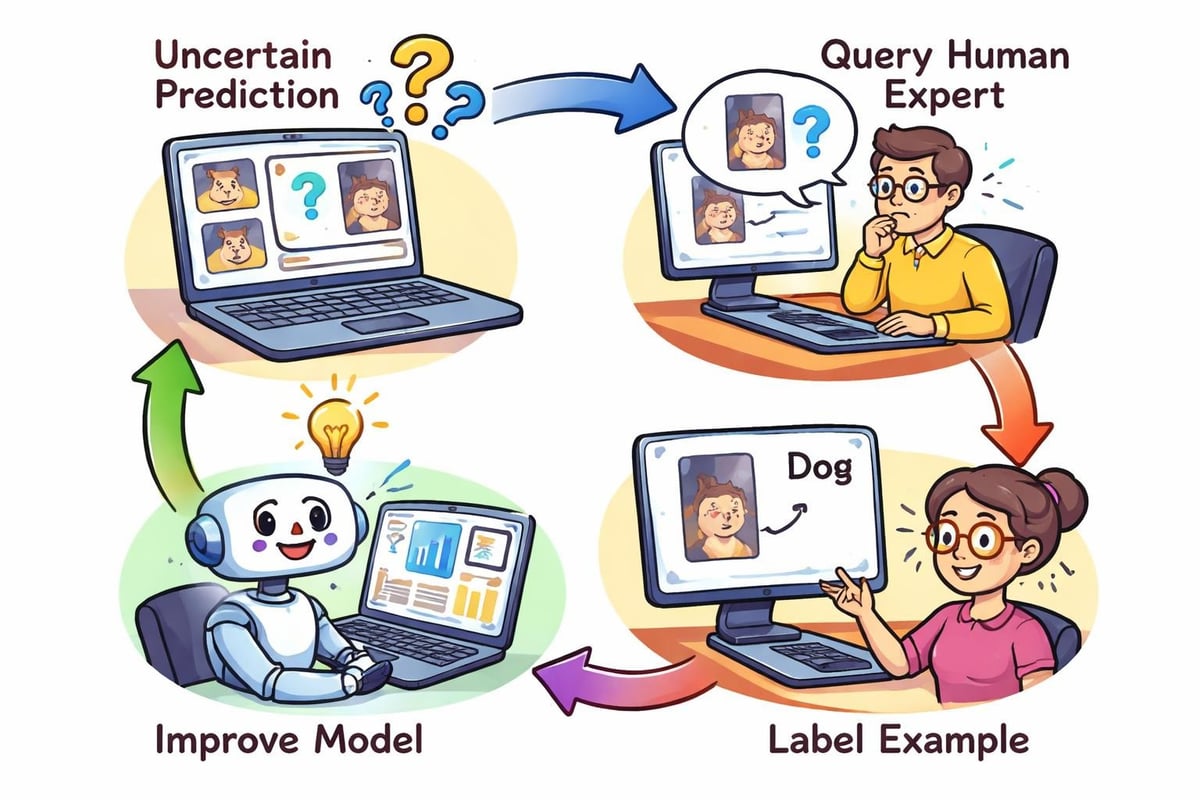
Aktywne uczenie się i szkolenia efektywne pod względem wykorzystania danych
Nie wszystkie przykłady szkoleniowe w równym stopniu przyczyniają się do wydajności modelu. Aktywne uczenie się strategicznie wybiera najbardziej informacyjne punkty danych do oznaczania, minimalizując wysiłek związany z adnotacjami wymagany do osiągnięcia docelowego poziomu dokładności.
Wdrażanie strategii zapytań
Techniki aktywnego uczenia się wykorzystują różne strategie do identyfikacji wartościowych przykładów bez etykiet. Próbkowanie niepewności wybiera przypadki, w których model wykazuje najmniejsze zaufanie, podczas gdy zapytanie przez komisję wykorzystuje rozbieżności między wieloma modelami do identyfikacji próbek zawierających informacje.
Podejścia te okazują się szczególnie cenne, gdy koszty etykietowania są wysokie lub czas ekspertów jest ograniczony. Obrazowanie medyczne, klasyfikacja dokumentów prawnych i wyspecjalizowane dziedziny techniczne odnoszą znaczne korzyści z wydajnych pod względem danych metod szkolenia sztucznej inteligencji opartych na uczeniu maszynowym, które maksymalizują naukę na podstawie minimalnej liczby etykietowanych przykładów.
Popularne strategie aktywnego uczenia się:
- Próbkowanie niepewności skupiające się na niejednoznacznych prognozach
- Zapytanie komitetowe wykorzystujące rozbieżności w modelach
- Oczekiwana zmiana modelu wybierająca przykłady o maksymalnym wpływie
- Próbkowanie różnorodności zapewniające szerokie pokrycie przestrzeni wejściowej
- Podejścia hybrydowe łączące wiele kryteriów wyboru
Zmniejszenie wymagań dotyczących adnotacji
Uczenie półnadzorowane łączy małe zestawy danych oznaczonych etykietami z obfitymi danymi nieoznaczonymi. Model początkowo uczy się na podstawie oznaczonych przykładów, a następnie wykorzystuje swoje przewidywania dotyczące danych nieoznaczonych do iteracyjnego doskonalenia. To podejście bootstrappingowe rozszerza możliwości szkolenia poza metody w pełni nadzorowane, wymagając jednocześnie znacznie mniejszego nakładu pracy związanego z oznaczaniem etykietami.
Uczenie samokontrolujące zwiększa efektywność danych poprzez tworzenie sygnałów nadzoru na podstawie samych danych. Modelowanie języka z maską, wykorzystywane do szkolenia dużych modeli językowych, przewiduje ukryte fragmenty tekstu na podstawie otaczającego kontekstu. Podobnie, uczenie kontrastowe tworzy nadzór poprzez odróżnianie podobnych przykładów od niepodobnych, umożliwiając tworzenie potężnych reprezentacji bez ręcznego oznaczania.
Kwestie etyczne i odpowiedzialne praktyki szkoleniowe
Szkolenie w zakresie uczenia maszynowego AI wiąże się z poważną odpowiedzialnością etyczną. Modele mogą nieumyślnie utrwalać uprzedzenia obecne w danych szkoleniowych, co prowadzi do dyskryminujących wyników w zastosowaniach o wysokiej stawce, takich jak zatrudnianie, udzielanie kredytów i wymiar sprawiedliwości w sprawach karnych.
Identyfikowanie i ograniczanie stronniczości w szkoleniach
Uprzedzenia przedostają się do szkolenia w zakresie uczenia maszynowego AI wieloma kanałami. Dane historyczne mogą odzwierciedlać przeszłą dyskryminację, metody pobierania próbek mogą nie odzwierciedlać w pełni niektórych populacji, a definicje etykiet mogą zawierać subiektywne oceny. Rozpoznanie tych źródeł stanowi pierwszy krok w kierunku ich łagodzenia.
Techniki eliminowania stronniczości obejmują ponowne pobieranie próbek w celu zrównoważenia reprezentacji, ponowne ważenie przykładów w celu wyrównania wpływu oraz eliminowanie stronniczości poprzez wyraźne karanie wzorców dyskryminacyjnych. Jednak same rozwiązania techniczne okazują się niewystarczające. Organizacje muszą ustanowić ramy zarządzania, które uwzględniają różnorodne perspektywy interesariuszy w całym cyklu rozwoju.
Badania dotyczące narzędzi etycznych AI i metod ich wdrażania podkreślają rozbieżność między zasadami etycznymi a praktycznym wdrażaniem. Przekładanie abstrakcyjnych wartości na konkretne praktyki szkoleniowe wymaga ciągłej uwagi, regularnych audytów i gotowości do iteracyjnego ulepszania modeli w miarę pojawiania się problemów.
Zapewnienie przejrzystości i zrozumiałości modeli
Modele typu „czarna skrzynka”, które zapewniają dokładne prognozy bez wyjaśnienia, budzą obawy w branżach regulowanych i w przypadku decyzji o wysokiej stawce. Techniki wyjaśnialnej sztucznej inteligencji pomagają interesariuszom zrozumieć, w jaki sposób modele dochodzą do wniosków, budując zaufanie i umożliwiając znaczący nadzór.
Metody wyjaśniania niezależne od modelu, takie jak LIME i SHAP, działają w różnych algorytmach, identyfikując cechy, które miały największy wpływ na konkretne prognozy. Mechanizmy uwagi w sieciach neuronowych ujawniają, na których częściach danych wejściowych skupił się model. Modele z natury interpretowalne, takie jak drzewa decyzyjne i regresja liniowa, poświęcają część mocy prognostycznej na rzecz pełnej przejrzystości.
Instytucje takie jak Kempner Institute for the Study of Natural and Artificial Intelligence prowadzą podstawowe badania nad mechanizmami inteligencji, które ostatecznie mogą zaowocować bardziej interpretowalnymi systemami sztucznej inteligencji. Tymczasem praktycy muszą znaleźć równowagę między dokładnością, wyjaśnialnością i względami etycznymi podczas projektowania metod szkoleniowych.
Ciągłe uczenie się i utrzymanie modelu
Wdrożenie wyszkolonego modelu stanowi raczej początek niż koniec cyklu szkolenia maszynowego uczenia się sztucznej inteligencji. Środowiska rzeczywiste zmieniają się w czasie, powodując pogorszenie wydajności modelu, ponieważ dane szkoleniowe stają się mniej reprezentatywne dla aktualnych warunków.
Monitorowanie wydajności modelu w środowisku produkcyjnym
Monitorowanie produkcji śledzi kluczowe wskaźniki wydajności w celu wykrycia, kiedy konieczne jest ponowne szkolenie. Dokładność, precyzja, przypomnienie i inne standardowe wskaźniki powinny być stale oceniane na podstawie nowych danych. Dryf koncepcyjny występuje, gdy zmienia się relacja między cechami a celami, natomiast dryf danych ma miejsce, gdy rozkłady danych wejściowych ulegają zmianie, nawet jeśli relacje pozostają stabilne.
Zautomatyzowane systemy monitorowania mogą generować alerty, gdy wydajność spadnie poniżej dopuszczalnych progów. Niektóre organizacje wdrażają stopniowe wprowadzanie nowych wersji modeli, stopniowo narażając je na rosnący ruch, jednocześnie monitorując problemy. Testy A/B porównują nowe modele z istniejącymi bazami odniesienia, aby zapewnić poprawę przed pełnym wdrożeniem.
Podstawowe elementy monitorowania obejmują:
- Śledzenie wskaźników wydajności w czasie rzeczywistym
- Monitorowanie dystrybucji danych w celu wykrywania odchyleń
- Pomiar opóźnień prognozowania i przepustowości
- Analiza błędów identyfikująca systematyczne wzorce awarii
- Zbieranie opinii od użytkowników końcowych i interesariuszy
Wdrażanie ciągłych procesów szkoleniowych
Ciągłe szkolenia automatyzują proces aktualizacji modeli w miarę napływania nowych danych. Zamiast okresowych ręcznych szkoleń, systemy automatycznie uwzględniają nowe przykłady, ponownie szkolą modele, weryfikują wydajność i wdrażają ulepszenia, gdy spełnione są progi jakości.
Takie podejście pozwala na aktualizowanie modeli zgodnie z ewoluującymi wzorcami, jednocześnie ograniczając ręczną interwencję. Wprowadza jednak nowe wyzwania związane z kontrolą wersji, procedurami przywracania poprzednich wersji i zapewnieniem wystarczającej walidacji przed wdrożeniem. Organizacje muszą ustanowić solidne praktyki MLOps, które traktują szkolenie modeli z taką samą rygorystycznością, jak tworzenie oprogramowania.
Specjaliści zajmujący się rozwijaniem tych umiejętności mogą zapoznać się z najlepszymi praktykami branżowymi oraz zdobyć praktyczne doświadczenie w zakresie nowoczesnych narzędzi i platform, korzystając z najlepszych kursów dotyczących uczenia maszynowego.
Strategie szkoleniowe w zakresie sztucznej inteligencji dla przedsiębiorstw
Organizacje stoją przed wyjątkowymi wyzwaniami podczas wdrażania szkoleń z zakresu uczenia maszynowego AI na dużą skalę. W przeciwieństwie do indywidualnych praktyków eksperymentujących z modelami, przedsiębiorstwa muszą brać pod uwagę kwestie związane z zarządzaniem, zgodnością z przepisami, współpracą zespołową i dostosowaniem do celów biznesowych.
Budowanie wewnętrznych możliwości szkoleniowych
Rozwój wewnętrznej wiedzy specjalistycznej wymaga strategicznych inwestycji w edukację i infrastrukturę. Organizacje powinny zidentyfikować przypadki użycia o wysokiej wartości, w których sztuczna inteligencja może zapewnić wymierny wpływ na działalność biznesową, a następnie stworzyć zespoły międzyfunkcyjne łączące wiedzę dziedzinową z umiejętnościami technicznymi.
Strukturalne programy szkoleniowe przyspieszają rozwój umiejętności. Korporacyjne programy certyfikacyjne zapewniają standardowe szkolenia, które gwarantują spójną podstawową wiedzę we wszystkich zespołach. Praktyczne projekty wykorzystujące techniki do rozwiązywania rzeczywistych problemów biznesowych utrwalają wiedzę, zapewniając jednocześnie wymierną wartość.
Mechanizmy dzielenia się wiedzą, takie jak wewnętrzne społeczności praktyków, regularne prezentacje techniczne i standardy dokumentacji, pomagają w rozpowszechnianiu wiedzy specjalistycznej poza grono początkowych praktyków. Programy mentorskie łączą doświadczonych praktyków z osobami rozwijającymi swoje umiejętności, tworząc zrównoważony transfer wiedzy.
Wybór platform i narzędzi szkoleniowych
Krajobraz technologiczny szkoleń z zakresu uczenia maszynowego AI nadal szybko się rozwija. Organizacje muszą oceniać platformy w oparciu o swoje konkretne wymagania, istniejącą infrastrukturę i możliwości zespołu. Rozwiązania oparte na chmurze oferują elastyczność i skalowalność, podczas gdy wdrożenia lokalne zapewniają większą kontrolę nad wrażliwymi danymi.
Platformy zarządzane eliminują złożoność infrastruktury, ale mogą powodować uzależnienie od dostawcy. Frameworki open source zapewniają elastyczność i przejrzystość, ale wymagają bardziej specjalistycznej wiedzy. Podejścia hybrydowe łączą komercyjne platformy do obciążeń produkcyjnych z narzędziami open source do eksperymentów i badań.
| Typ platformy | Zalety | Wady | Najlepsze zastosowanie |
|---|---|---|---|
| Zarządzana w chmurze | Szybka konfiguracja, automatyczne skalowanie | Bieżące koszty, potencjalna zależność od dostawcy | Szybkie wdrożenie, zmienne obciążenia |
| Oprogramowanie open source | Elastyczność, brak kosztów licencji | Wymaga wiedzy specjalistycznej, samodzielne zarządzanie | Dostosowanie, ograniczenia budżetowe |
| Przedsiębiorstwo | Wsparcie, funkcje zarządzania | Wysokie koszty, złożoność | Duże organizacje, wymagania dotyczące zgodności |
| Hybrydowe | Zrównoważone podejście | Złożoność integracji | Różnorodne wymagania |
Pojawiające się trendy kształtujące metodyki szkoleniowe
Dziedzina szkolenia w zakresie uczenia maszynowego AI nadal szybko się rozwija, a nowe techniki i podejścia pojawiają się regularnie. Bycie na bieżąco z tymi zmianami pomaga organizacjom utrzymać przewagę konkurencyjną i wdrażać bardziej efektywne metody szkoleniowe.
Modele podstawowe i uczenie się na niewielkiej liczbie przykładów
Duże modele podstawowe, trenowane na ogromnych zbiorach danych, wykazują niezwykłą zdolność do dostosowywania się do nowych zadań przy minimalnym dodatkowym szkoleniu. Uczenie się na podstawie niewielkiej liczby przykładów umożliwia tym modelom dobre wykonywanie nowych zadań przy użyciu zaledwie kilku przykładów, co znacznie zmniejsza wymagania dotyczące danych, które historycznie ograniczały wdrażanie sztucznej inteligencji.
Ta zmiana paradygmatu zmienia podejście organizacji do szkolenia w zakresie uczenia maszynowego AI. Zamiast gromadzić tysiące oznaczonych przykładów dla każdej nowej aplikacji, zespoły mogą dostosowywać istniejące modele przy użyciu niewielkich zbiorów danych. Ta dostępność umożliwia mniejszym organizacjom wdrażanie zaawansowanej sztucznej inteligencji bez konieczności posiadania zasobów, które były wcześniej wymagane.
Automatyczne uczenie maszynowe i wyszukiwanie architektury neuronowej
Platformy AutoML automatyzują tradycyjnie ręczne aspekty tworzenia modeli, od inżynierii cech, poprzez wybór architektury, aż po optymalizację hiperparametrów. Systemy te demokratyzują sztuczną inteligencję, umożliwiając praktykom o ograniczonej wiedzy specjalistycznej tworzenie skutecznych modeli, a jednocześnie pozwalając doświadczonym praktykom skupić się na strategii wyższego poziomu.
Wyszukiwanie architektury neuronowej automatycznie odkrywa optymalne struktury sieci dla określonych zadań. Zamiast polegać na ludzkiej intuicji dotyczącej konfiguracji warstw i połączeń, systemy te badają rozległe przestrzenie architektury w celu zidentyfikowania najlepszych projektów. Wraz ze spadkiem kosztów obliczeniowych podejścia te prawdopodobnie staną się standardową praktyką w procesach szkolenia uczenia maszynowego AI.
Standaryzacja i najlepsze praktyki
Wysiłki branży na rzecz standaryzacji pomagają ustanowić wspólne ramy rozwoju sztucznej inteligencji. Zalecenie ITU-T Y.3181 zawiera wytyczne architektoniczne dotyczące integracji uczenia maszynowego z infrastrukturą sieciową, a różne konsorcja branżowe pracują nad standardami interoperacyjności.
Publikacje takie jak „Machine Learning and Knowledge Extraction” (Uczenie maszynowe i pozyskiwanie wiedzy) rozpowszechniają wyniki badań, które stanowią podstawę dla ewoluujących najlepszych praktyk. W miarę dojrzewania tej dziedziny znormalizowane podejścia do walidacji, testowania i wdrażania pomogą organizacjom w bardziej niezawodnym i wydajnym wdrażaniu sztucznej inteligencji.
Opanowanie szkolenia z zakresu uczenia maszynowego wymaga zrozumienia podstawowych pojęć, wdrożenia najlepszych praktyk i śledzenia na bieżąco szybko ewoluujących technik. Organizacje, które strategicznie inwestują w rozwój tych umiejętności, są w stanie wykorzystać transformacyjny potencjał sztucznej inteligencji, jednocześnie odpowiedzialnie podchodząc do kwestii etycznych. MammothClub zapewnia kompleksowe ścieżki edukacyjne, praktyczne bootcampy i korporacyjne programy certyfikacyjne, które pomagają profesjonalistom i zespołom szybko zdobyć praktyczne umiejętności w zakresie sztucznej inteligencji. Dzięki ponad 3000 kursów obejmujących wszystko, od podstawowych pojęć po zaawansowane techniki, nasza platforma zapewnia infrastrukturę szkoleniową, której organizacje potrzebują, aby skutecznie konkurować w erze sztucznej inteligencji.


