The rapid evolution of artificial intelligence has transformed how organizations approach technology implementation and workforce development. At the heart of this transformation lies ai machine learning training, a critical process that enables algorithms to learn from data and make intelligent decisions without explicit programming. Understanding the fundamentals of training machine learning models has become essential for professionals seeking to leverage AI's full potential, whether they're data scientists, business analysts, or technology leaders driving digital transformation initiatives.
Understanding the Fundamentals of AI Machine Learning Training
AI machine learning training represents the systematic process of feeding data into algorithms to help them recognize patterns, make predictions, and improve performance over time. This foundational concept distinguishes modern AI from traditional rule-based programming approaches.
The Core Components of Training Architecture
Every successful ai machine learning training initiative relies on several interconnected elements that work together to produce accurate, reliable models. The training data serves as the foundation, providing examples from which algorithms extract meaningful patterns and relationships.
Essential training components include:
- Training datasets with labeled examples for supervised learning
- Algorithm selection based on problem complexity and data characteristics
- Hyperparameter configuration to optimize model performance
- Validation frameworks to prevent overfitting and ensure generalization
- Computational infrastructure to handle processing demands
The quality of your training data directly impacts model performance, as research has consistently demonstrated. Studies examining data quality effects on machine learning performance reveal that inconsistencies, biases, and incompleteness in training datasets can significantly undermine model accuracy and reliability.
Supervised vs. Unsupervised Training Approaches
Different learning paradigms require distinct training methodologies. Supervised learning trains models using labeled data where correct answers are known, enabling algorithms to learn input-output mappings. This approach dominates applications like image classification, speech recognition, and predictive analytics.
Unsupervised learning, conversely, discovers hidden patterns in unlabeled data without predetermined categories. Training unsupervised models involves configuring algorithms to identify clusters, associations, and anomalies independently. Semi-supervised and reinforcement learning represent hybrid approaches that combine elements from both paradigms.
| Training Paradigm | Data Requirements | Common Applications | Complexity Level |
|---|---|---|---|
| Supervised | Labeled datasets | Classification, regression | Moderate |
| Unsupervised | Unlabeled data | Clustering, dimensionality reduction | High |
| Semi-supervised | Partially labeled | Text classification, image recognition | High |
| Reinforcement | Reward signals | Game playing, robotics | Very High |
Building Effective Training Pipelines
Creating robust ai machine learning training pipelines requires careful planning and systematic execution. The pipeline transforms raw data into deployable models through structured workflows that ensure consistency and reproducibility.
Data Preparation and Feature Engineering
Data preparation consumes approximately 80% of time in typical machine learning projects. This crucial phase involves collecting relevant data, cleaning inconsistencies, handling missing values, and transforming features into formats algorithms can process effectively.
Feature engineering represents the art of selecting and creating variables that best represent underlying patterns. Domain expertise becomes invaluable here, as understanding business context helps identify which features will most strongly influence model predictions. For professionals seeking to develop these skills, exploring comprehensive AI and ML learning paths provides structured guidance through these technical concepts.
Critical data preparation steps:
- Data collection from multiple sources and formats
- Data cleaning to remove duplicates and correct errors
- Feature scaling to normalize value ranges
- Feature selection to identify most predictive variables
- Data splitting into training, validation, and test sets
Model Selection and Architecture Design
Choosing appropriate algorithms depends on problem characteristics, data volume, and performance requirements. Decision trees excel at interpretability, neural networks handle complex non-linear relationships, and ensemble methods combine multiple models for enhanced accuracy.
Deep learning architectures introduce additional complexity to ai machine learning training. Convolutional neural networks process visual data efficiently, recurrent networks handle sequential information, and transformer architectures have revolutionized natural language processing. Each architecture requires specific training strategies and computational resources, particularly when working with GPUs optimized for AI training.
Advanced Training Techniques and Optimization
Modern ai machine learning training incorporates sophisticated techniques that accelerate learning, improve accuracy, and reduce computational costs. These advanced methods separate adequate models from exceptional ones.
Transfer Learning and Pre-trained Models
Transfer learning leverages knowledge from models trained on large datasets to jumpstart training on related tasks. Rather than training from scratch, practitioners fine-tune pre-trained models using smaller, task-specific datasets. This approach dramatically reduces training time and data requirements while often improving final model performance.
The proliferation of pre-trained models has democratized access to state-of-the-art AI capabilities. Organizations can now implement sophisticated solutions without the massive computational resources previously required. However, understanding when and how to apply transfer learning requires solid theoretical foundations that beginner AI courses can provide.
Hyperparameter Tuning and Model Optimization
Hyperparameters control the learning process itself rather than being learned from data. Learning rate, batch size, number of layers, and regularization strength all significantly impact training outcomes. Systematic hyperparameter tuning often separates mediocre results from breakthrough performance.
Common optimization strategies include:
- Grid search examining all parameter combinations
- Random search sampling parameter space efficiently
- Bayesian optimization using probabilistic models
- Automated machine learning (AutoML) platforms
- Neural architecture search for deep learning
According to the Artificial Intelligence Index Report 2024, organizations increasingly adopt automated approaches to hyperparameter optimization, reducing the manual effort traditionally required while discovering superior configurations that human practitioners might overlook.
Distributed and Federated Training Approaches
As datasets and models grow larger, single-machine training becomes impractical. Distributed training parallelizes computation across multiple processors or machines, enabling organizations to train models that would otherwise be impossible.
Scaling Training Across Infrastructure
Cloud platforms like Amazon SageMaker provide managed environments for distributed ai machine learning training. These platforms abstract infrastructure complexity, automatically distributing workloads and managing resource allocation. Data parallelism splits training data across multiple workers, while model parallelism divides the model itself when it exceeds single-device memory capacity.
Infrastructure decisions significantly impact training efficiency and cost. Organizations must balance performance requirements against budget constraints, considering factors like processor types, memory configurations, and network bandwidth. Understanding these tradeoffs helps technology leaders make informed infrastructure investments.
Federated Learning for Privacy-Preserving Training
Federated learning enables collaborative model training without centralizing sensitive data. Devices train local models on their data, sharing only model updates rather than raw information. The central server aggregates these updates to improve the global model, which is redistributed for further local training.
Research into federated learning frameworks has accelerated development of privacy-preserving ai machine learning training techniques. This approach particularly benefits healthcare, finance, and other sectors where data privacy regulations restrict information sharing. The Munich Center for Machine Learning actively researches federated approaches alongside other cutting-edge training methodologies.
| Training Approach | Data Location | Privacy Level | Complexity | Best Use Cases |
|---|---|---|---|---|
| Centralized | Single server | Low | Low | Non-sensitive applications |
| Distributed | Multiple servers | Low | Moderate | Large-scale training |
| Federated | Edge devices | High | High | Privacy-sensitive domains |
| Hybrid | Mixed | Moderate | High | Complex regulatory environments |
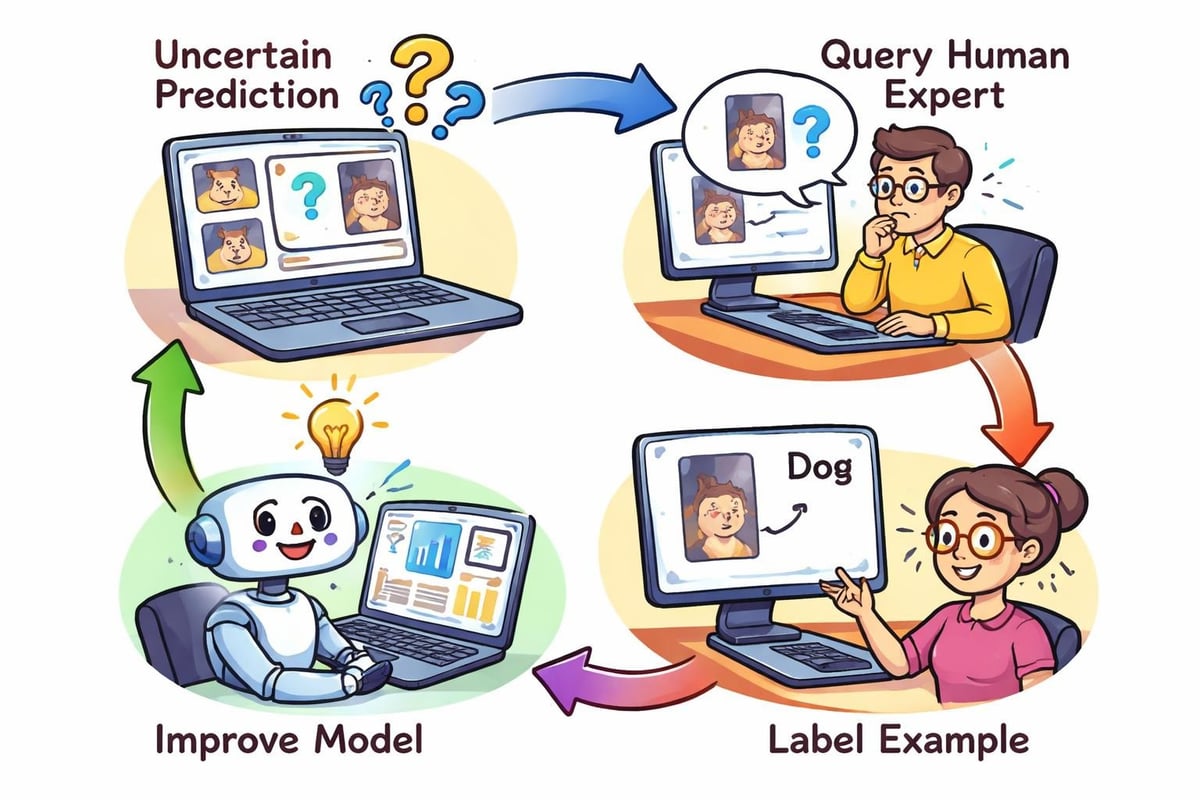
Active Learning and Data-Efficient Training
Not all training examples contribute equally to model performance. Active learning strategically selects the most informative data points for labeling, minimizing the annotation effort required to achieve target accuracy levels.
Implementing Query Strategies
Active learning techniques employ various strategies to identify valuable unlabeled examples. Uncertainty sampling selects instances where the model exhibits least confidence, while query-by-committee uses disagreement among multiple models to identify informative samples.
These approaches prove particularly valuable when labeling costs are high or expert time is limited. Medical imaging, legal document classification, and specialized technical domains benefit significantly from data-efficient ai machine learning training methods that maximize learning from minimal labeled examples.
Popular active learning strategies:
- Uncertainty sampling focusing on ambiguous predictions
- Query-by-committee leveraging model disagreement
- Expected model change selecting maximum-impact examples
- Diversity sampling ensuring broad coverage of input space
- Hybrid approaches combining multiple selection criteria
Reducing Annotation Requirements
Semi-supervised learning combines small labeled datasets with abundant unlabeled data. The model learns from labeled examples initially, then uses its predictions on unlabeled data to iteratively improve. This bootstrapping approach extends training capacity beyond fully supervised methods while requiring substantially less labeling effort.
Self-supervised learning takes data efficiency further by creating supervision signals from the data itself. Masked language modeling, used to train large language models, predicts hidden portions of text using surrounding context. Similarly, contrastive learning creates supervision by distinguishing similar examples from dissimilar ones, enabling powerful representations without manual labels.
Ethical Considerations and Responsible Training Practices
AI machine learning training carries significant ethical responsibilities. Models can inadvertently perpetuate biases present in training data, leading to discriminatory outcomes in high-stakes applications like hiring, lending, and criminal justice.
Identifying and Mitigating Training Bias
Bias enters ai machine learning training through multiple channels. Historical data may reflect past discrimination, sampling methods might underrepresent certain populations, and label definitions can encode subjective judgments. Recognizing these sources represents the first step toward mitigation.
Techniques for addressing bias include resampling to balance representation, reweighting examples to equalize influence, and adversarial debiasing that explicitly penalizes discriminatory patterns. However, technical solutions alone prove insufficient. Organizations must establish governance frameworks that include diverse stakeholder perspectives throughout the development lifecycle.
Research reviewing AI ethics tools and implementation methods highlights the gap between ethical principles and practical implementation. Translating abstract values into concrete training practices requires ongoing attention, regular audits, and willingness to iteratively improve models as issues emerge.
Ensuring Model Transparency and Explainability
Black-box models that provide accurate predictions without explanation raise concerns in regulated industries and high-stakes decisions. Explainable AI techniques help stakeholders understand how models arrive at conclusions, building trust and enabling meaningful oversight.
Model-agnostic explanation methods like LIME and SHAP work across different algorithms, identifying which features most influenced specific predictions. Attention mechanisms in neural networks reveal which input portions the model focused on. Inherently interpretable models like decision trees and linear regression sacrifice some predictive power for complete transparency.
Institutions like the Kempner Institute for the Study of Natural and Artificial Intelligence conduct fundamental research into intelligence mechanisms that may ultimately yield more interpretable AI systems. Meanwhile, practitioners must balance accuracy, explainability, and ethical considerations when designing training approaches.
Continuous Learning and Model Maintenance
Deploying a trained model represents the beginning rather than end of the ai machine learning training lifecycle. Real-world environments change over time, causing model performance to degrade as training data becomes less representative of current conditions.
Monitoring Model Performance in Production
Production monitoring tracks key performance metrics to detect when retraining becomes necessary. Accuracy, precision, recall, and other standard metrics should be continuously evaluated on fresh data. Concept drift occurs when the relationship between features and targets changes, while data drift happens when input distributions shift even if relationships remain stable.
Automated monitoring systems can trigger alerts when performance degrades beyond acceptable thresholds. Some organizations implement staged rollouts, gradually exposing new model versions to increasing traffic while monitoring for issues. A/B testing compares new models against existing baselines to ensure improvements before full deployment.
Essential monitoring components include:
- Real-time performance metric tracking
- Data distribution monitoring for drift detection
- Prediction latency and throughput measurement
- Error analysis identifying systematic failure patterns
- Feedback collection from end users and stakeholders
Implementing Continuous Training Pipelines
Continuous training automates the process of updating models as new data arrives. Rather than periodic manual retraining, systems automatically incorporate fresh examples, retrain models, validate performance, and deploy improvements when quality thresholds are met.
This approach keeps models current with evolving patterns while reducing manual intervention. However, it introduces new challenges around version control, rollback procedures, and ensuring sufficient validation before deployment. Organizations must establish robust MLOps practices that treat model training with the same rigor as software development.
For professionals developing these capabilities, exploring top machine learning courses provides exposure to industry best practices and hands-on experience with modern tools and platforms.
Enterprise AI Training Strategies
Organizations face unique challenges when implementing ai machine learning training at scale. Unlike individual practitioners experimenting with models, enterprises must consider governance, compliance, team collaboration, and alignment with business objectives.
Building Internal Training Capabilities
Developing internal expertise requires strategic investment in education and infrastructure. Organizations should identify high-value use cases where AI can deliver measurable business impact, then assemble cross-functional teams combining domain knowledge with technical skills.
Structured learning programs accelerate capability development. Corporate certification programs provide standardized training that ensures consistent baseline knowledge across teams. Hands-on projects applying techniques to real business problems cement learning while delivering tangible value.
Knowledge sharing mechanisms like internal communities of practice, regular technical presentations, and documentation standards help distribute expertise beyond initial practitioners. Mentorship programs pair experienced practitioners with those developing skills, creating sustainable knowledge transfer.
Selecting Training Platforms and Tools
The technology landscape for ai machine learning training continues expanding rapidly. Organizations must evaluate platforms based on their specific requirements, existing infrastructure, and team capabilities. Cloud-based solutions offer flexibility and scalability, while on-premises deployments provide greater control over sensitive data.
Managed platforms abstract infrastructure complexity but may introduce vendor lock-in. Open-source frameworks provide flexibility and transparency but require more specialized expertise. Hybrid approaches combine commercial platforms for production workloads with open-source tools for experimentation and research.
| Platform Type | Advantages | Disadvantages | Best For |
|---|---|---|---|
| Cloud Managed | Quick setup, automatic scaling | Ongoing costs, potential lock-in | Rapid deployment, variable workloads |
| Open Source | Flexibility, no licensing costs | Requires expertise, self-managed | Customization, budget constraints |
| Enterprise | Support, governance features | High cost, complexity | Large organizations, compliance needs |
| Hybrid | Balanced approach | Integration complexity | Mixed requirements |
Emerging Trends Shaping Training Methodologies
The field of ai machine learning training continues evolving rapidly, with new techniques and approaches emerging regularly. Staying current with these developments helps organizations maintain competitive advantages and adopt more efficient training methods.
Foundation Models and Few-Shot Learning
Large foundation models trained on massive datasets exhibit remarkable abilities to adapt to new tasks with minimal additional training. Few-shot learning enables these models to perform well on novel tasks using only a handful of examples, dramatically reducing the data requirements that historically limited AI adoption.
This paradigm shift changes how organizations approach ai machine learning training. Rather than collecting thousands of labeled examples for each new application, teams can fine-tune pre-existing models using small datasets. This accessibility enables smaller organizations to implement sophisticated AI without the resources previously required.
Automated Machine Learning and Neural Architecture Search
AutoML platforms automate traditionally manual aspects of model development, from feature engineering through architecture selection to hyperparameter optimization. These systems democratize AI by enabling practitioners with limited expertise to build effective models while freeing experienced practitioners to focus on higher-level strategy.
Neural architecture search automatically discovers optimal network structures for specific tasks. Rather than relying on human intuition about layer configurations and connections, these systems explore vast architecture spaces to identify superior designs. As computational costs decrease, these approaches will likely become standard practice in ai machine learning training workflows.
Standardization and Best Practices
Industry efforts toward standardization help establish common frameworks for AI development. The ITU-T Recommendation Y.3181 provides architectural guidance for integrating machine learning into network infrastructure, while various industry consortiums work toward interoperability standards.
Publications like Machine Learning and Knowledge Extraction disseminate research findings that inform evolving best practices. As the field matures, standardized approaches to validation, testing, and deployment will help organizations implement AI more reliably and efficiently.
Mastering ai machine learning training requires understanding fundamental concepts, implementing best practices, and staying current with rapidly evolving techniques. Organizations that invest strategically in developing these capabilities position themselves to leverage AI's transformative potential while navigating ethical considerations responsibly. MammothClub provides comprehensive learning paths, hands-on bootcamps, and corporate certification programs that help professionals and teams build practical AI skills quickly. With 3,000+ courses covering everything from foundational concepts to advanced techniques, our platform delivers the training infrastructure organizations need to compete effectively in the AI era.


